Scale Your Metrics with Elasticsearch
A presentation at HighLoad++ in in Moscow, Russia by Philipp Krenn

Scale Your Metrics with Elasticsearch Philipp Krenn @xeraa


$ curl http://localhost:9200 { "name" : "elasticsearch-hot", "cluster_name" : "metrics-cluster", "cluster_uuid" : "06nHPLLgTrmZEpYli6JW5w", "version" : { "number" : "6.5.0", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "c53b7d3", "build_date" : "2018-11-08T21:28:50.577384Z", "build_snapshot" : false, "lucene_version" : "7.5.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }








I'm not going to use a search engine for metrics. — Too often

Developer
Questions: https://sli.do/xeraa Answers: Live or https://twitter.com/xeraa

Agenda Building Blocks Architecture Demo

Building Blocks

Only accept features that scale. — https://github.com/elastic/engineering/blob/master/ development_constitution.md

Horizontal Scaling Shards Replication Writes & Reads

Cluster, Node, Index, Shard

Write Coordinating Node, Hash, Primary, Replica(s)

Get & Aggregate Coordinating Node, Hash, Shard

Search Coordinating Node, Query then Fetch

Append-Only Optimization IDs assigned on coordinating node Fast add instead of the slow update

Lucene Segments index.refresh_interval: 1s 7.0: index.search.idle.after

Storage Compression LZ4 (default) DEFLATE (best_compression)

BKD Trees Points in Lucene
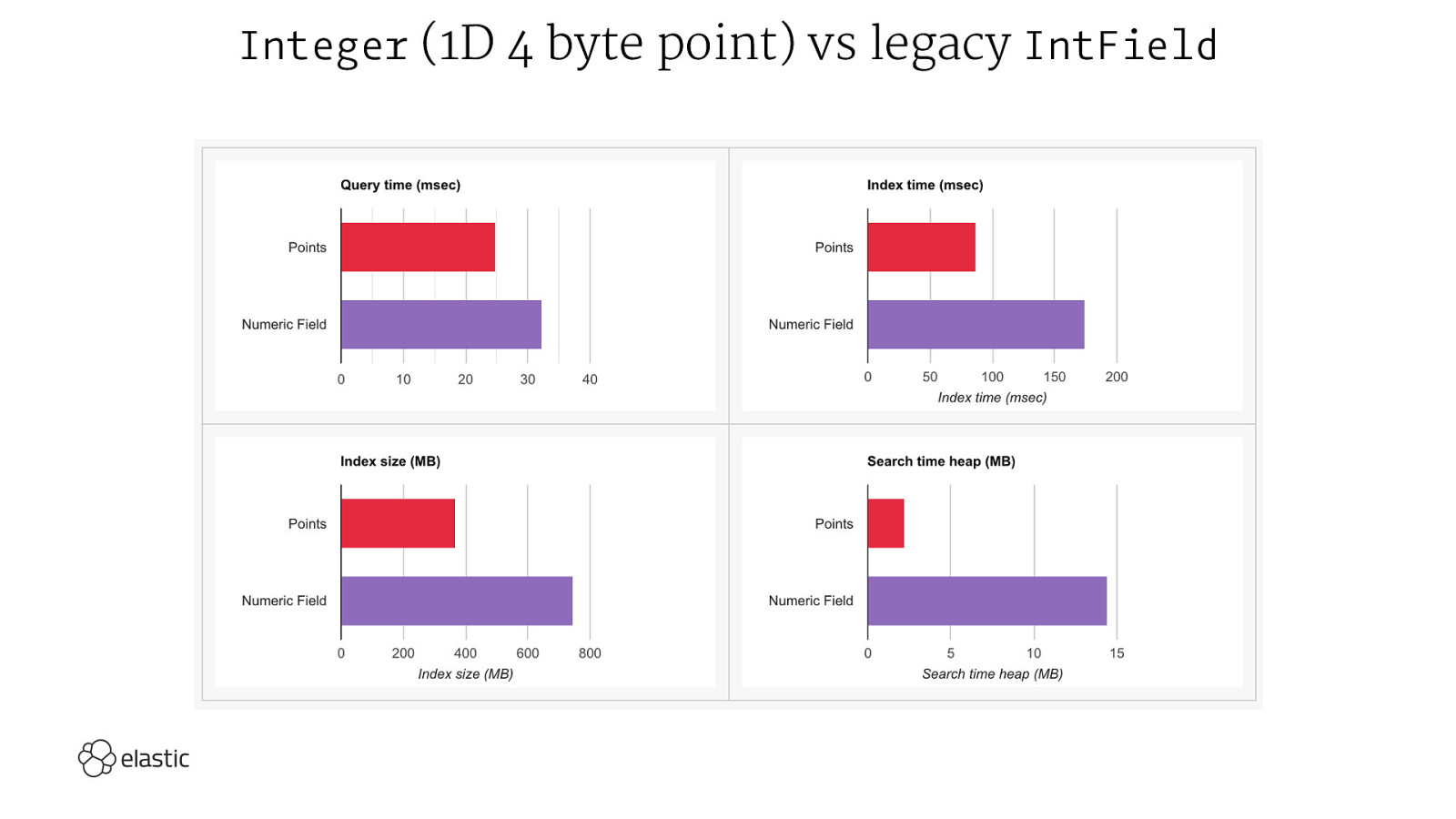
Integer (1D 4 byte point) vs legacy IntField

Half & Scaled Floats
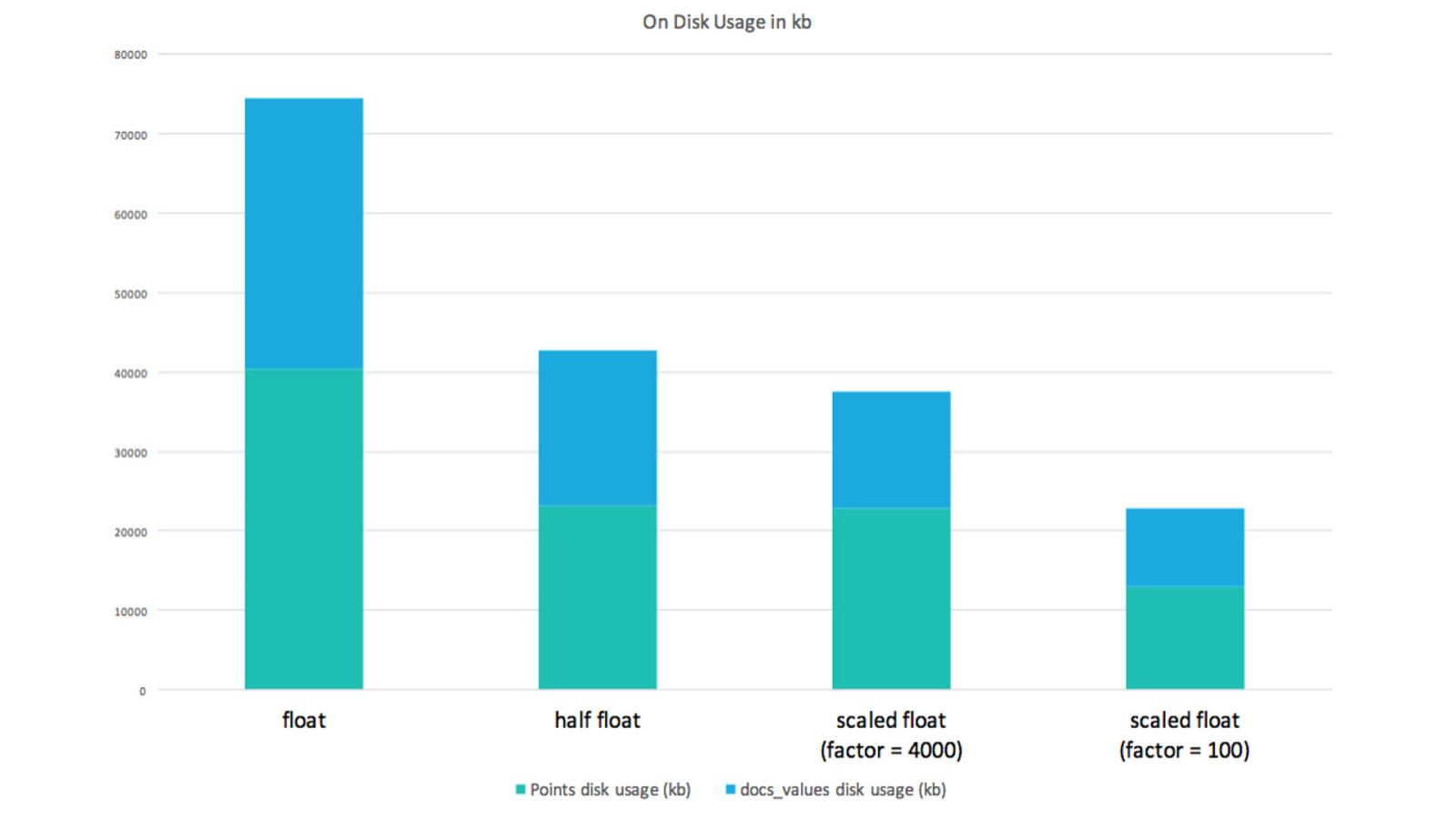

https://github.com/elastic/beats/blob/master/metricbeat/module/system/load/_meta/ fields.yml - name: load type: group description: > CPU load averages. release: ga fields: - name: "1" type: scaled_float scaling_factor: 100 description: > Load average for the last minute. - name: "5" type: scaled_float scaling_factor: 100 description: > Load average for the last 5 minutes. ...

_all Removal https://www.elastic.co/guide/en/elasticsearch/reference/ current/mapping-all-field.html

Doc Values Replaced Fielddata https://www.elastic.co/guide/en/elasticsearch/guide/ current/_deep_dive_on_doc_values.html

Architecture

Time Based Indices index: "metricbeat-%{[beat.version]}-%{+yyyy.MM.dd}"

Rollover Indices Condition when to switch

PUT /metricbeat-000001 { "aliases": { "metricbeat": {} } } # Add >1000 documents to metricbeat-000001 POST /metricbeat/_rollover { "conditions": { } } "max_age": "1d", "max_docs": 1000, "max_size": "5gb"

{ "acknowledged": true, "shards_acknowledged": true, "old_index": "metricbeat-000001", "new_index": "metricbeat-000002", "rolled_over": true, "dry_run": false, "conditions": { "[max_age: 1d]": false, "[max_docs: 1000]": true, "[max_size: 5gb]": false, } }

Rollups

PUT _xpack/rollup/job/metricbeat { "id": "metricbeat", "index_pattern": "metricbeat-*", "rollup_index": "metricbeat_rollup", "cron": "0 * * * * ?", "page_size": 1000, "groups": { "date_histogram": { "interval": "5m", "delay": "5m", "time_zone": "UTC", "field": "@timestamp" },

"terms": { "fields": [ "docker.container.id" ] } }, "metrics": [ { "field": "docker.network.in.bytes", "metrics": [ "sum" ] }, { "field": "docker.network.out.bytes", "metrics": [ "sum" ] } ] }

Nodes! "
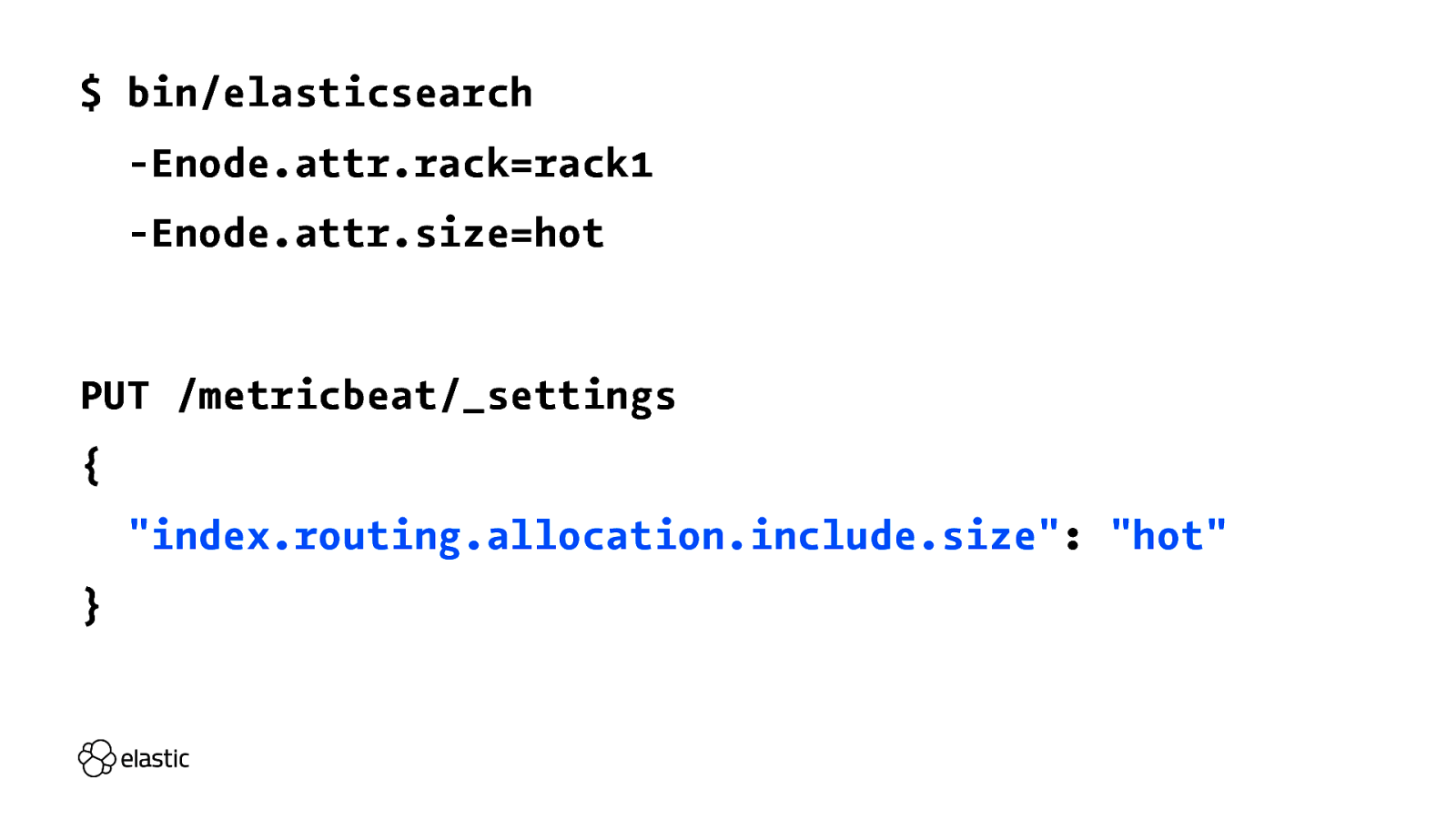
$ bin/elasticsearch -Enode.attr.rack=rack1 -Enode.attr.size=hot PUT /metricbeat/_settings { "index.routing.allocation.include.size": "hot" }

Cross Cluster Search Tribe Node

Cross Cluster Replication

Demo

Index Lifecycle Management Currently https://github.com/elastic/curator
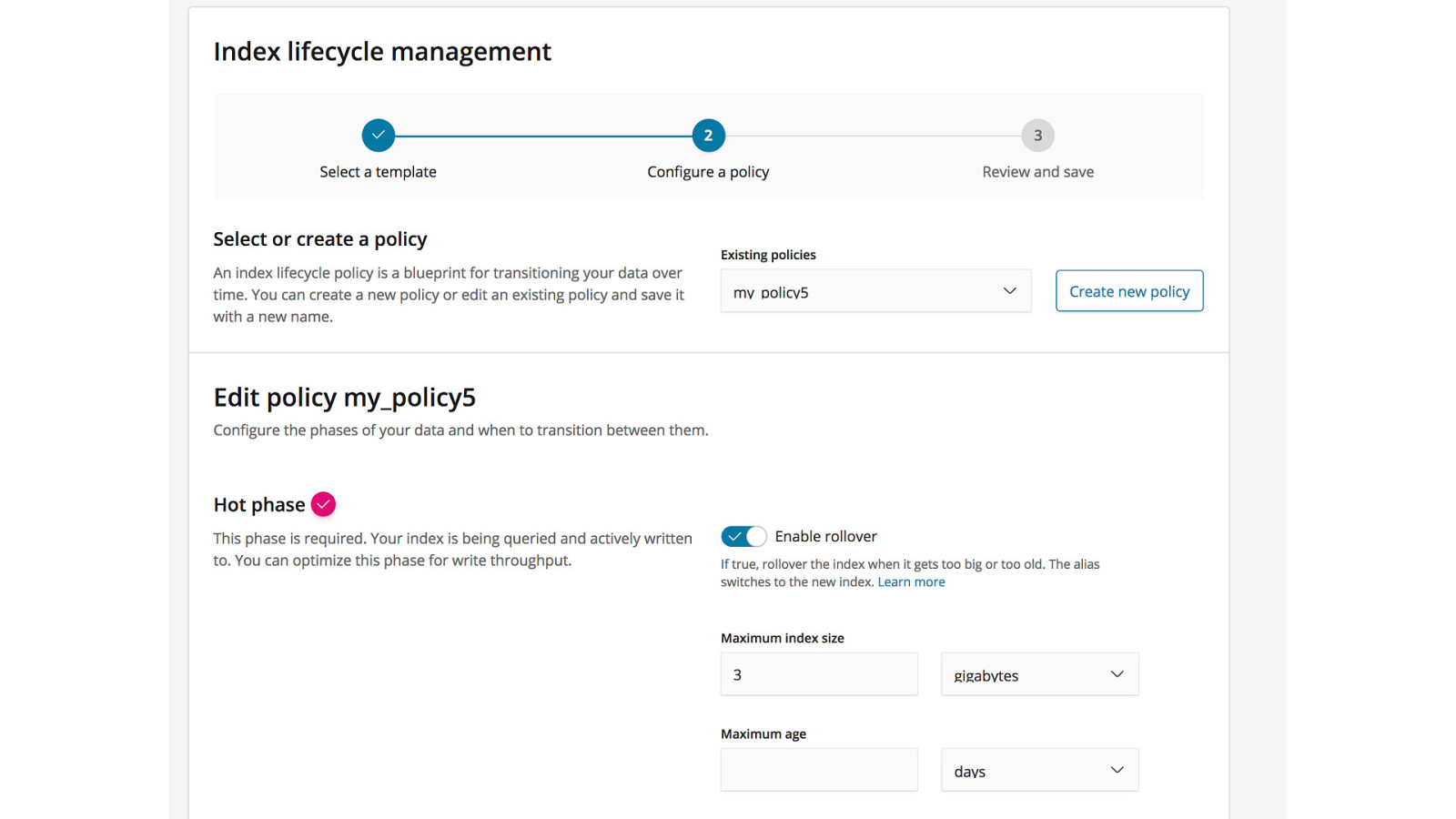
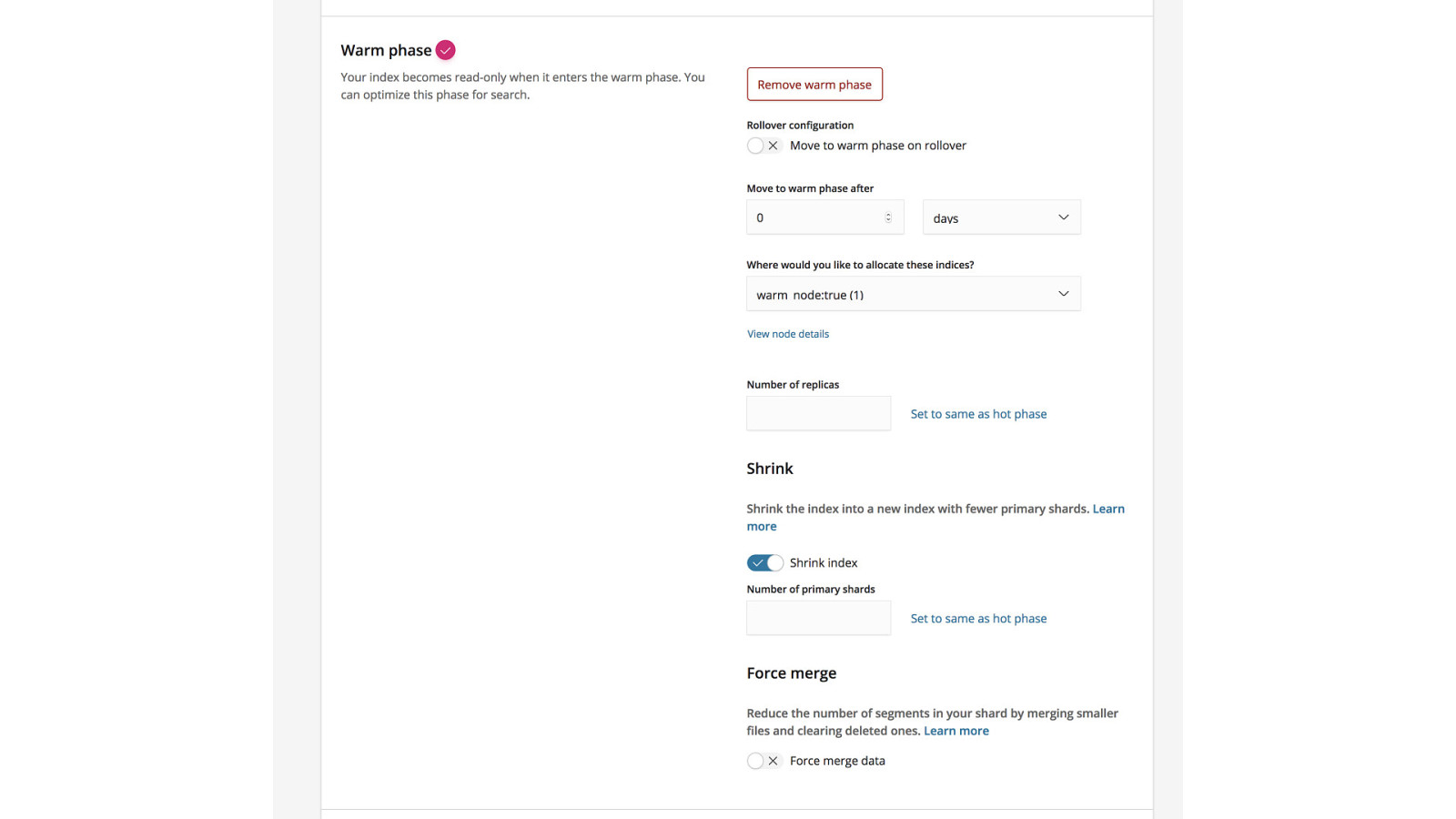
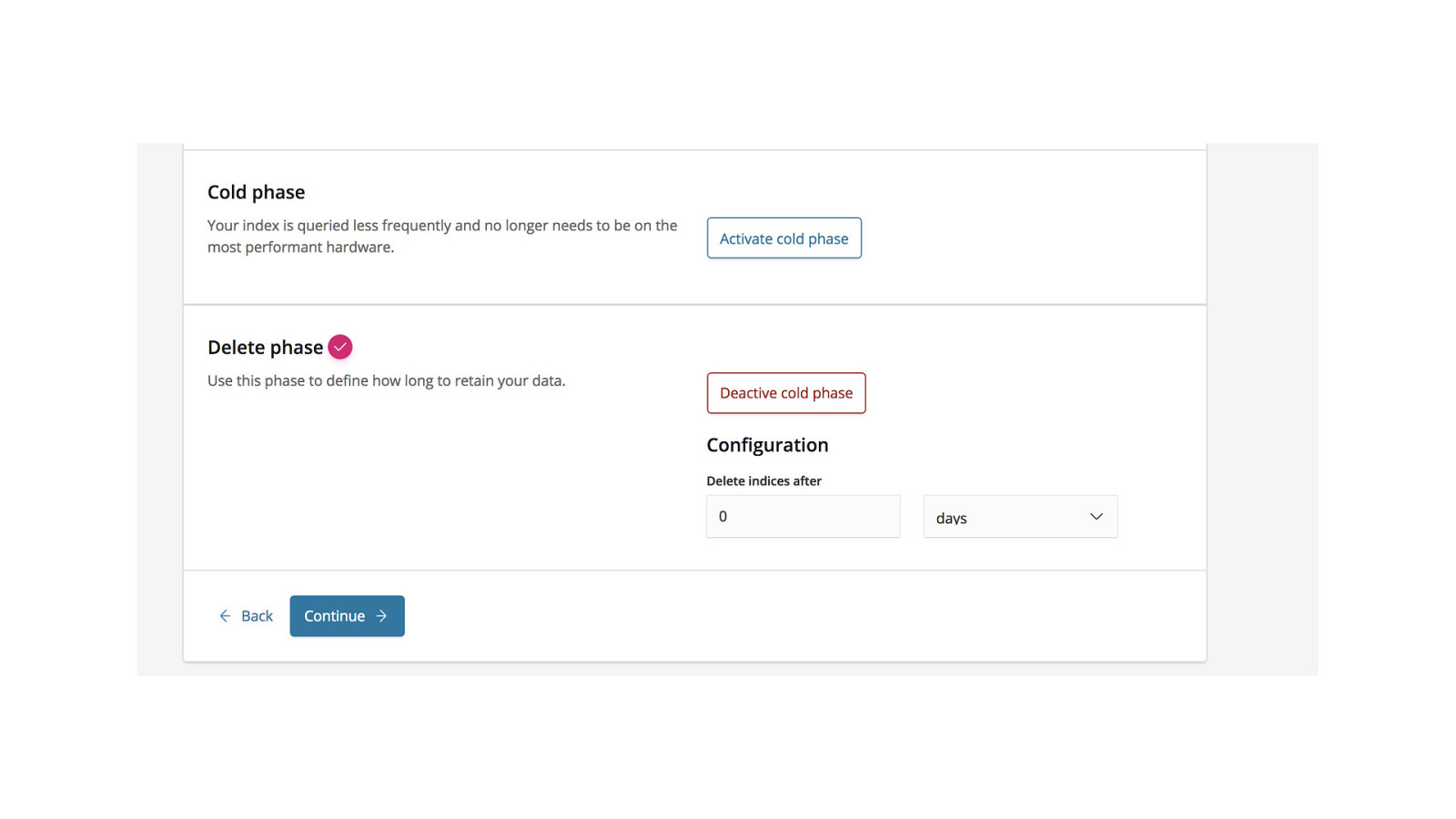

Frozen Indices Close + lazy open and release search resources

Conclusion

Agenda Building Blocks Architecture Demo

Benchmarks Fair Reproducible Close to Production


From to !

Questions? Philipp Krenn @xeraa

"Only accept features that scale" is one of Elasticsearch's engineering principles. So how do we scale metrics stored in Elasticsearch? And is that even possible on a full-text search engine?
This talk explores:
- How are metrics stored in Elasticsearch and how does this translate to disk use as well as query performance?
- What does an efficient multi-tier architecture look like to balance speed for today's data against density for older metrics?
- How can you compress old data and what does the mathematical model look like for different metrics?
We are trying all of this hands-on during the talk, since this has become much simpler recently.
 for free. You
can too.
for free. You
can too.
Video
Resources
The following resources were mentioned during the presentation or are useful additional information.
Buzz and feedback
Here’s what was said about this presentation on social media.