Scale Your Metrics with Elasticsearch
A presentation at DevOpsStage in in Kyiv, Ukraine, 02000 by Philipp Krenn

Scale Your Metrics with Elasticsearch Philipp Krenn @xeraa

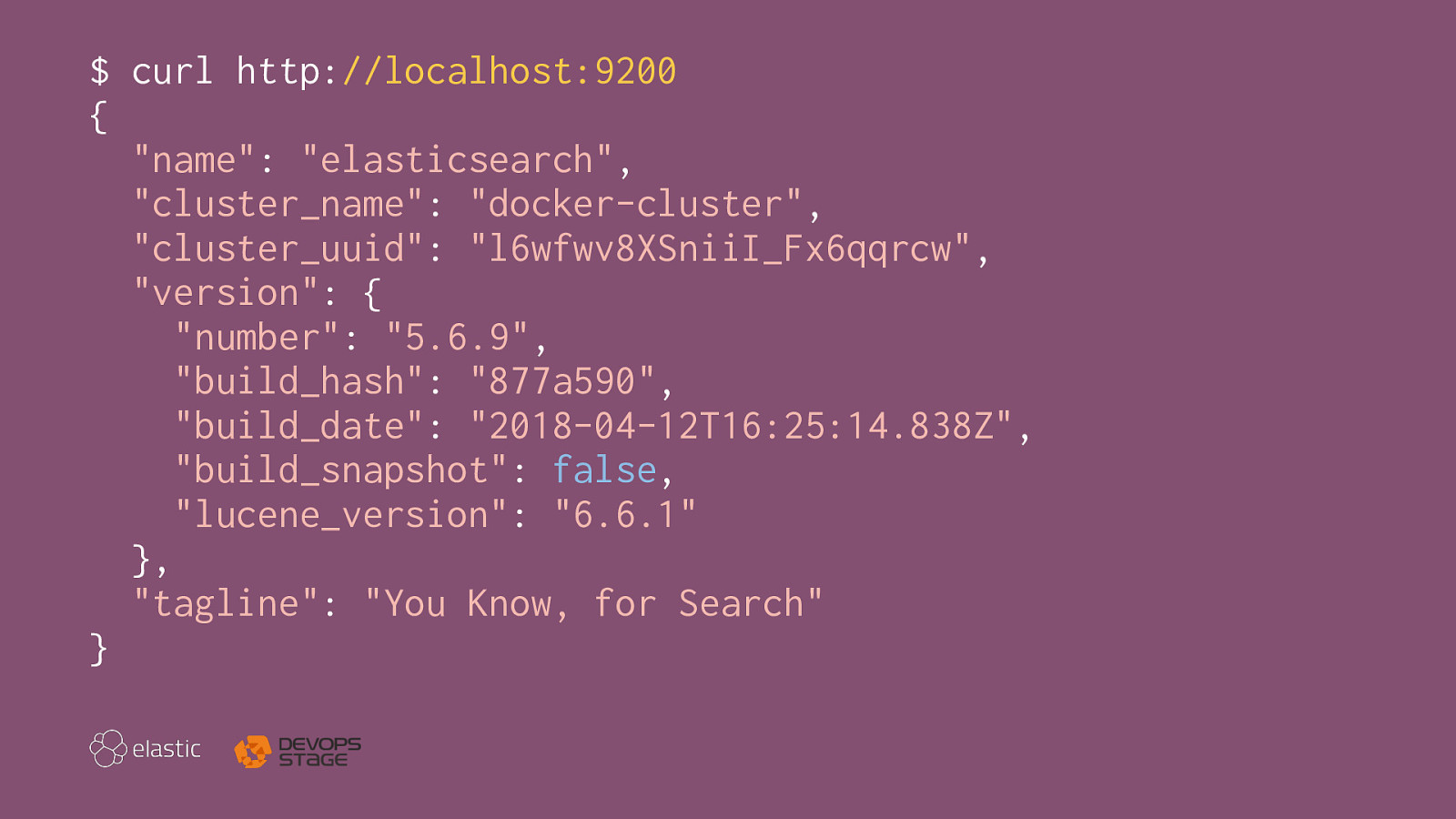
$ curl http://localhost:9200 { "name": "elasticsearch", "cluster_name": "docker-cluster", "cluster_uuid": "l6wfwv8XSniiI_Fx6qqrcw", "version": { "number": "5.6.9", "build_hash": "877a590", "build_date": "2018-04-12T16:25:14.838Z", "build_snapshot": false, "lucene_version": "6.6.1" }, "tagline": "You Know, for Search" }
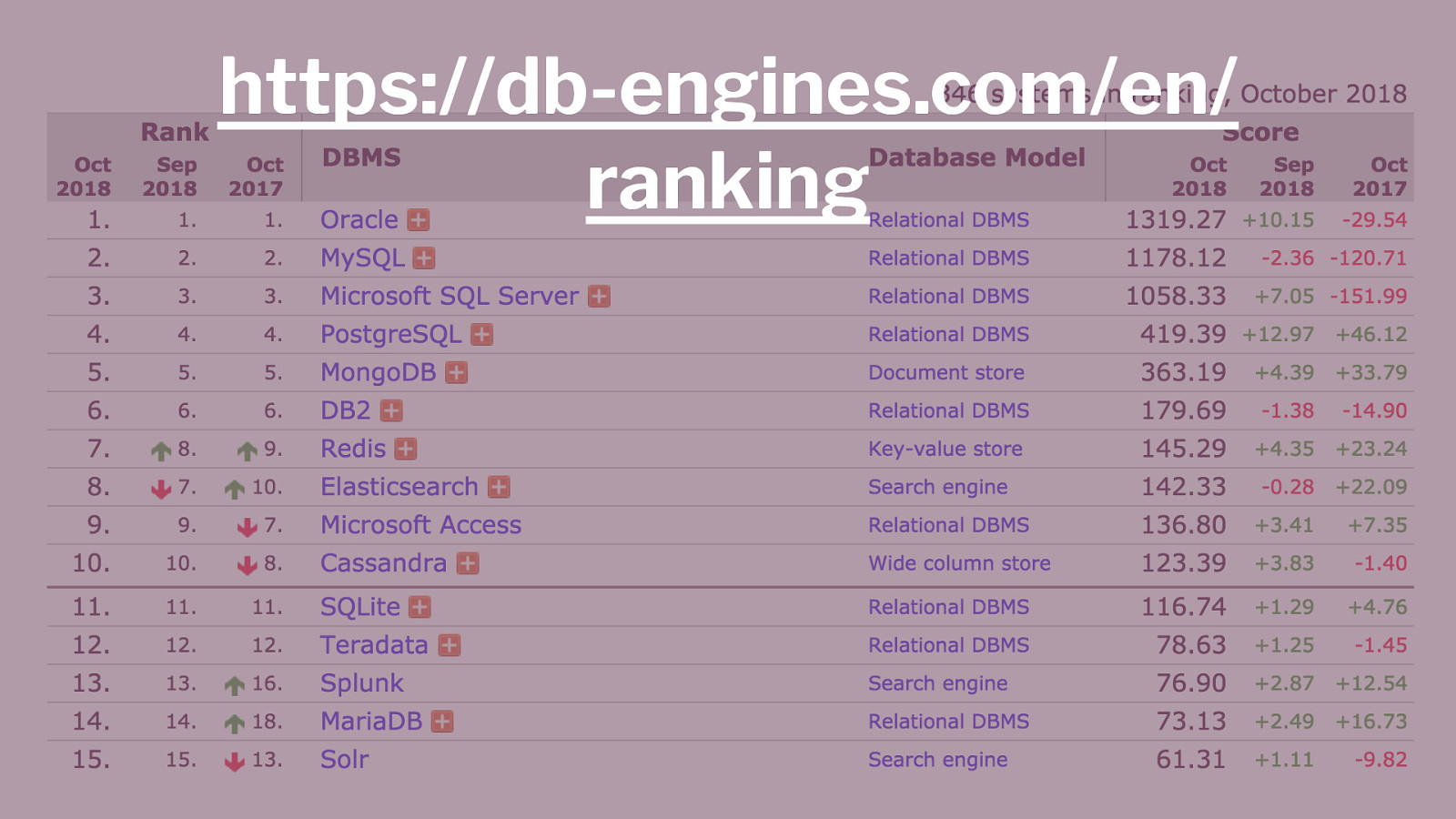
https://db-engines.com/en/ ranking


Full-Text Search


Logs




Metrics

I'm not going to use a search engine for metrics. — Too o!en

Developer

Agenda Building Blocks Tuning Delivering

Building Blocks

Only accept features that scale. — https://github.com/elastic/engineering/blob/ master/development_constitution.md

Horizontal Scaling Shards Replication Writes & Reads
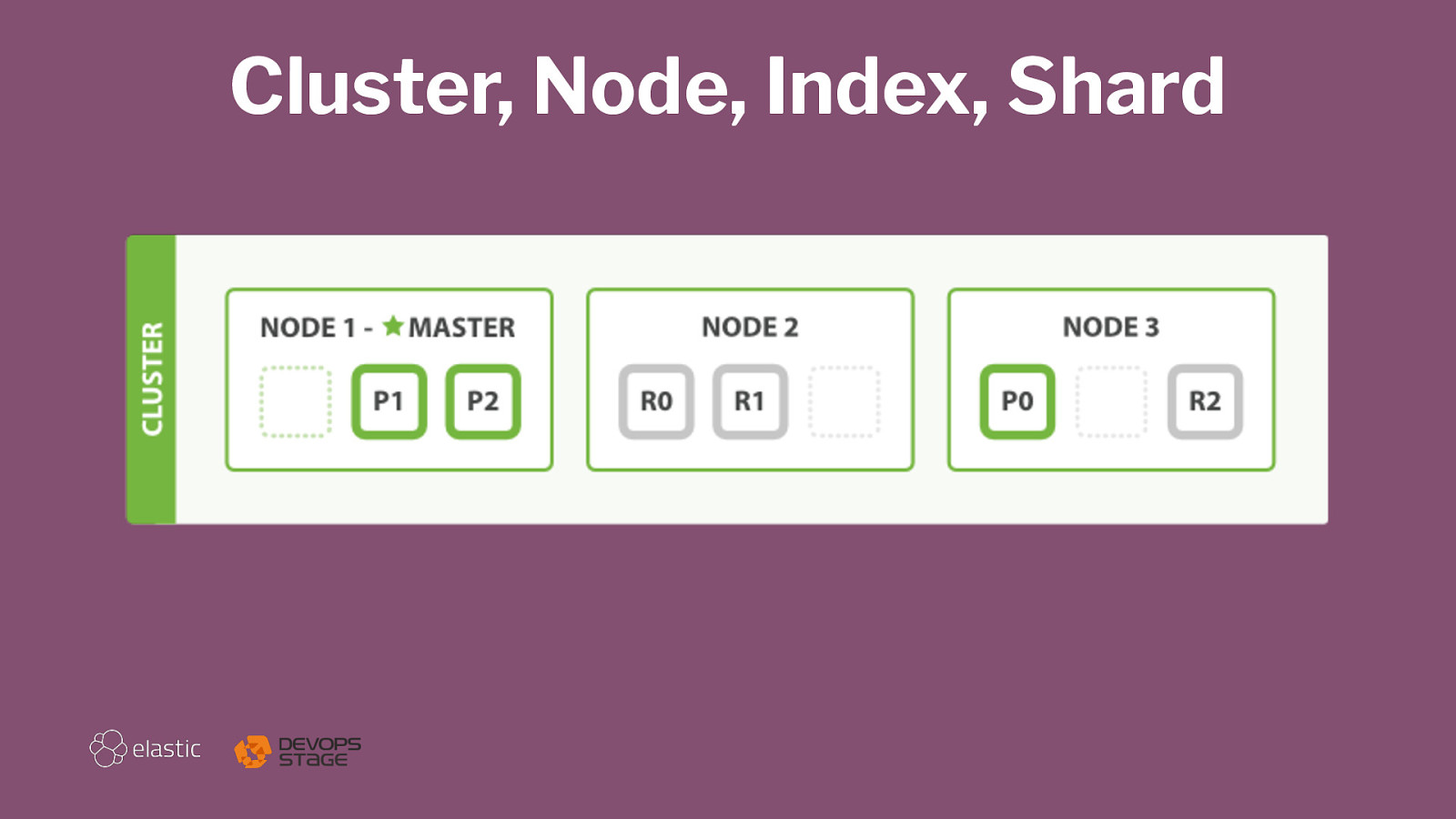
Cluster, Node, Index, Shard
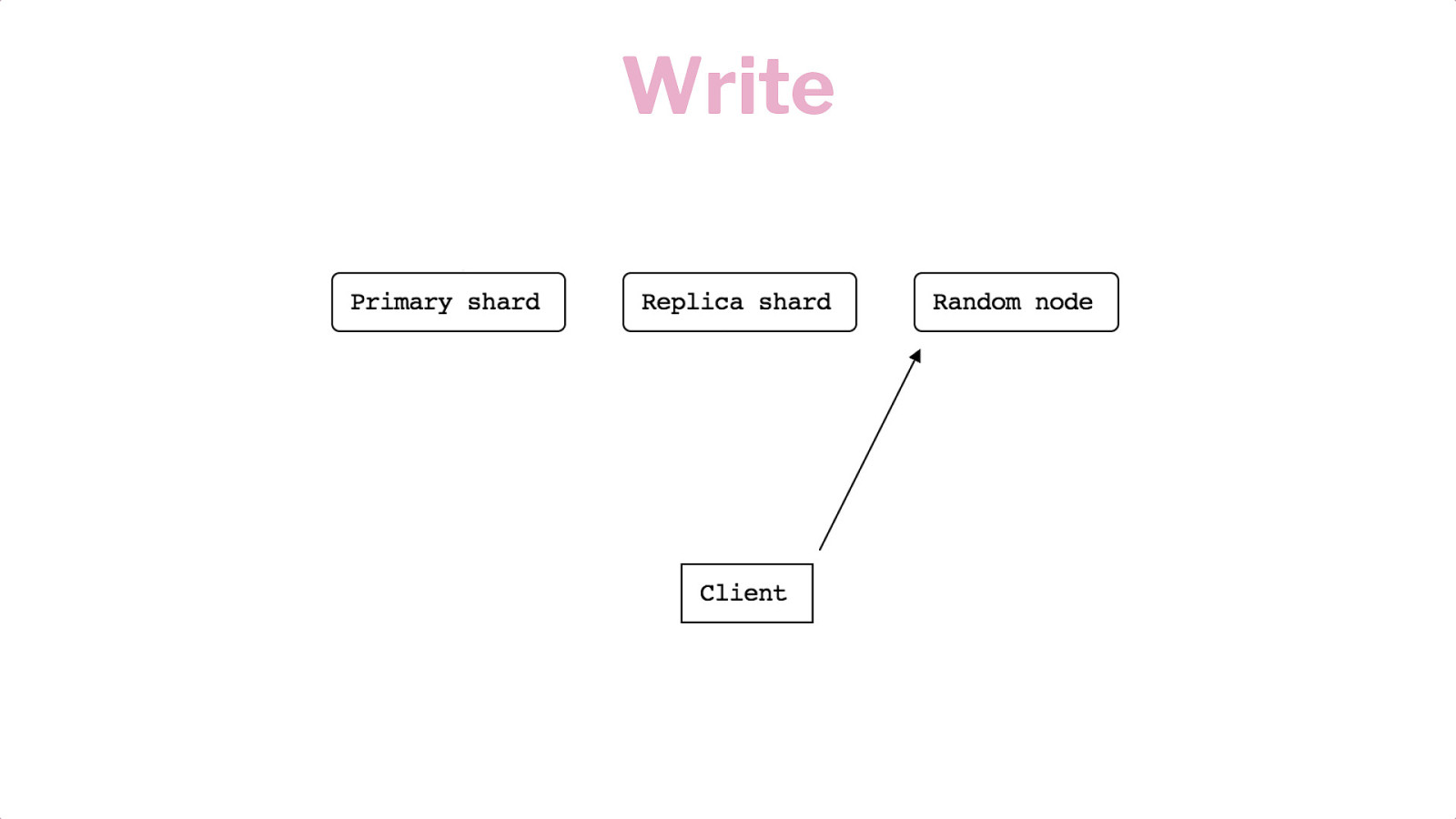
Write
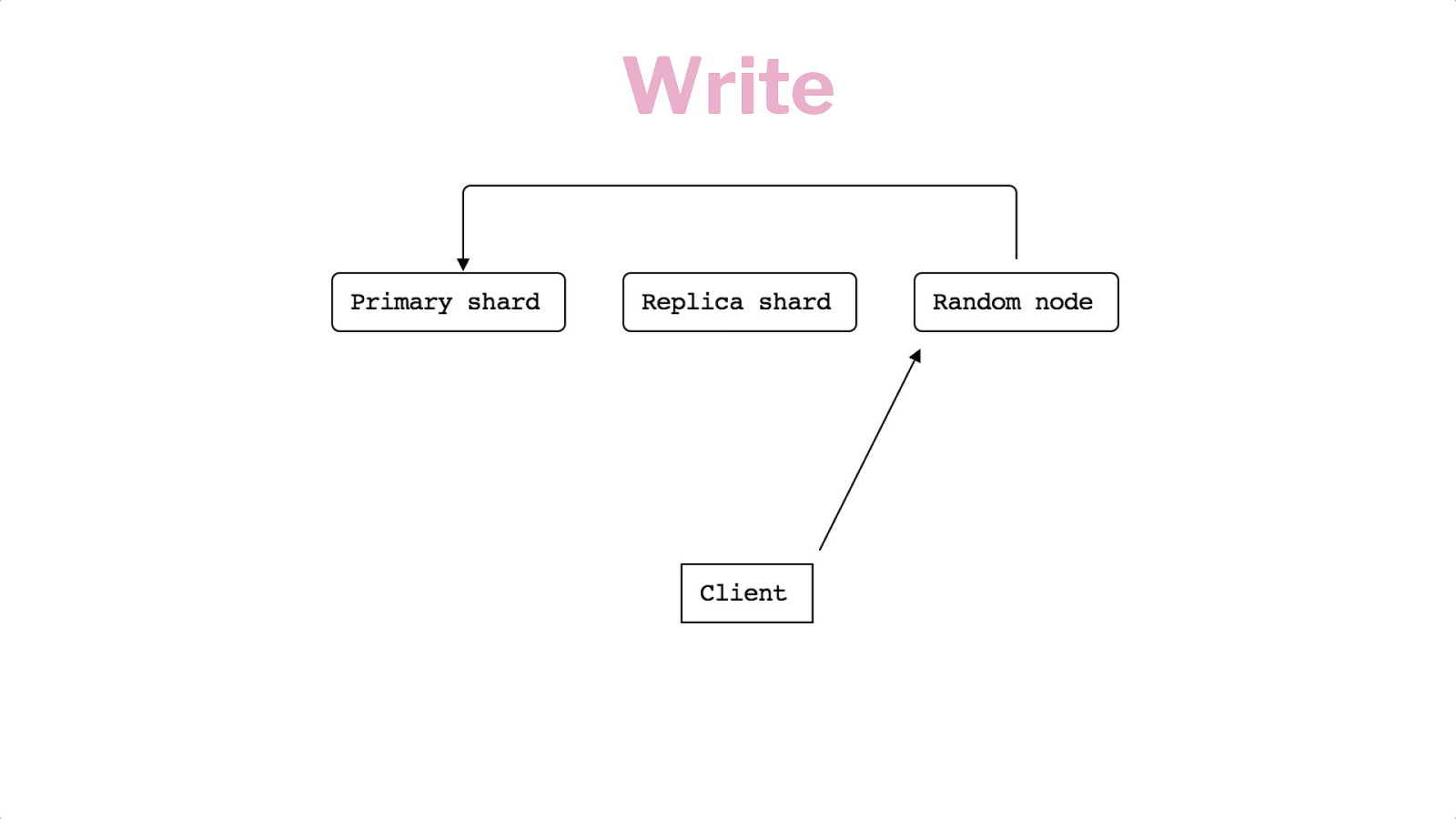
Write
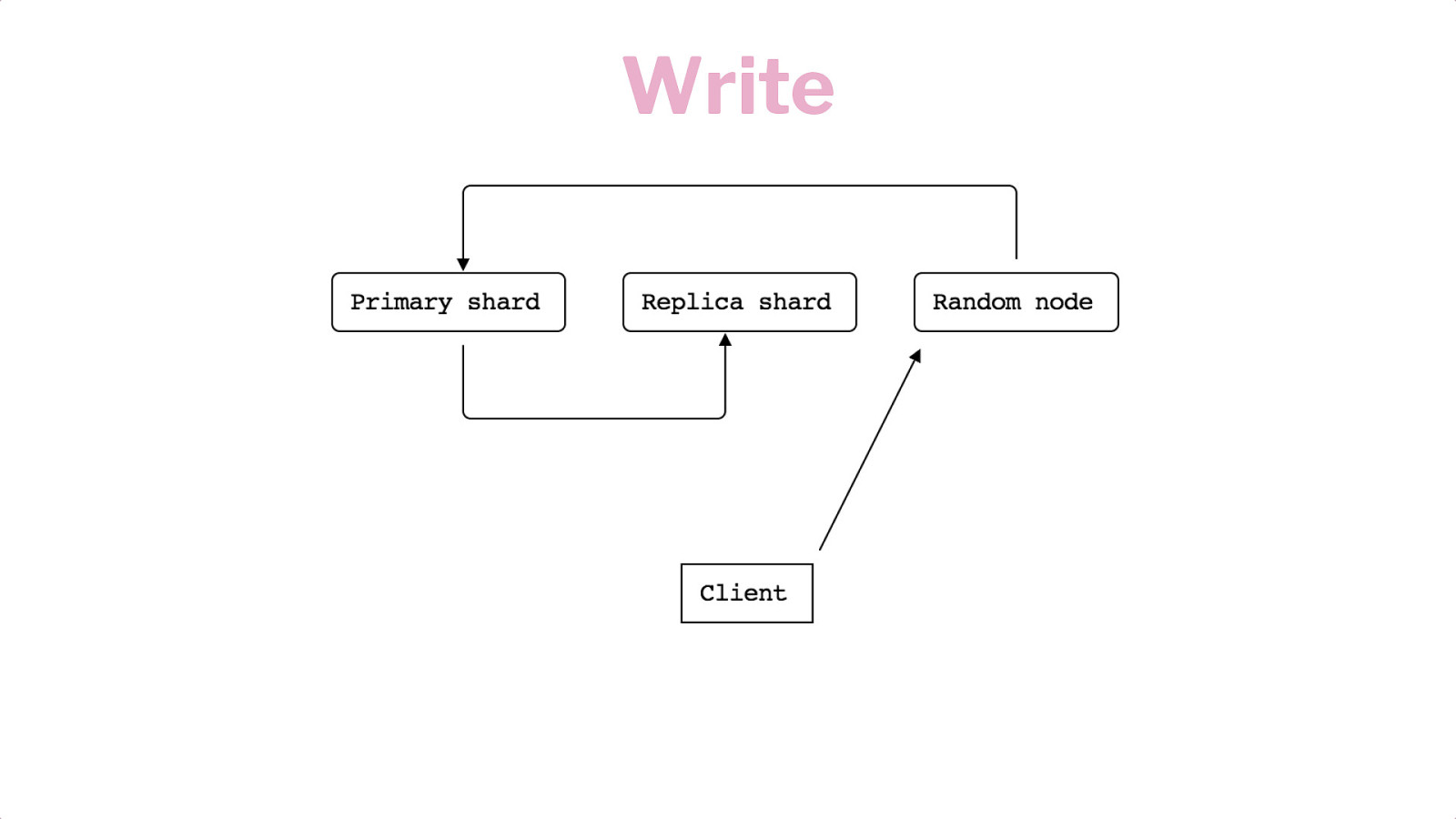
Write
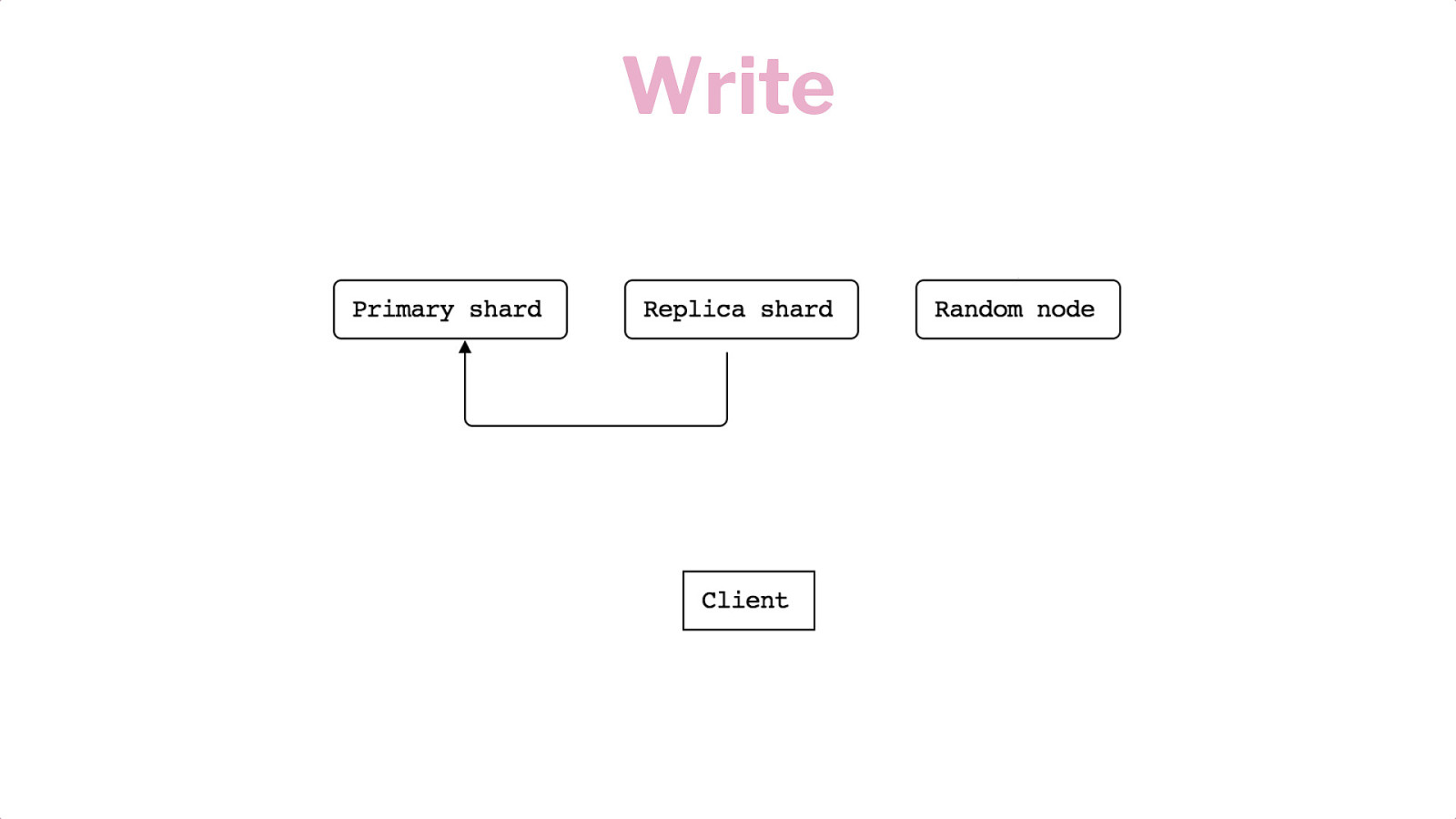
Write
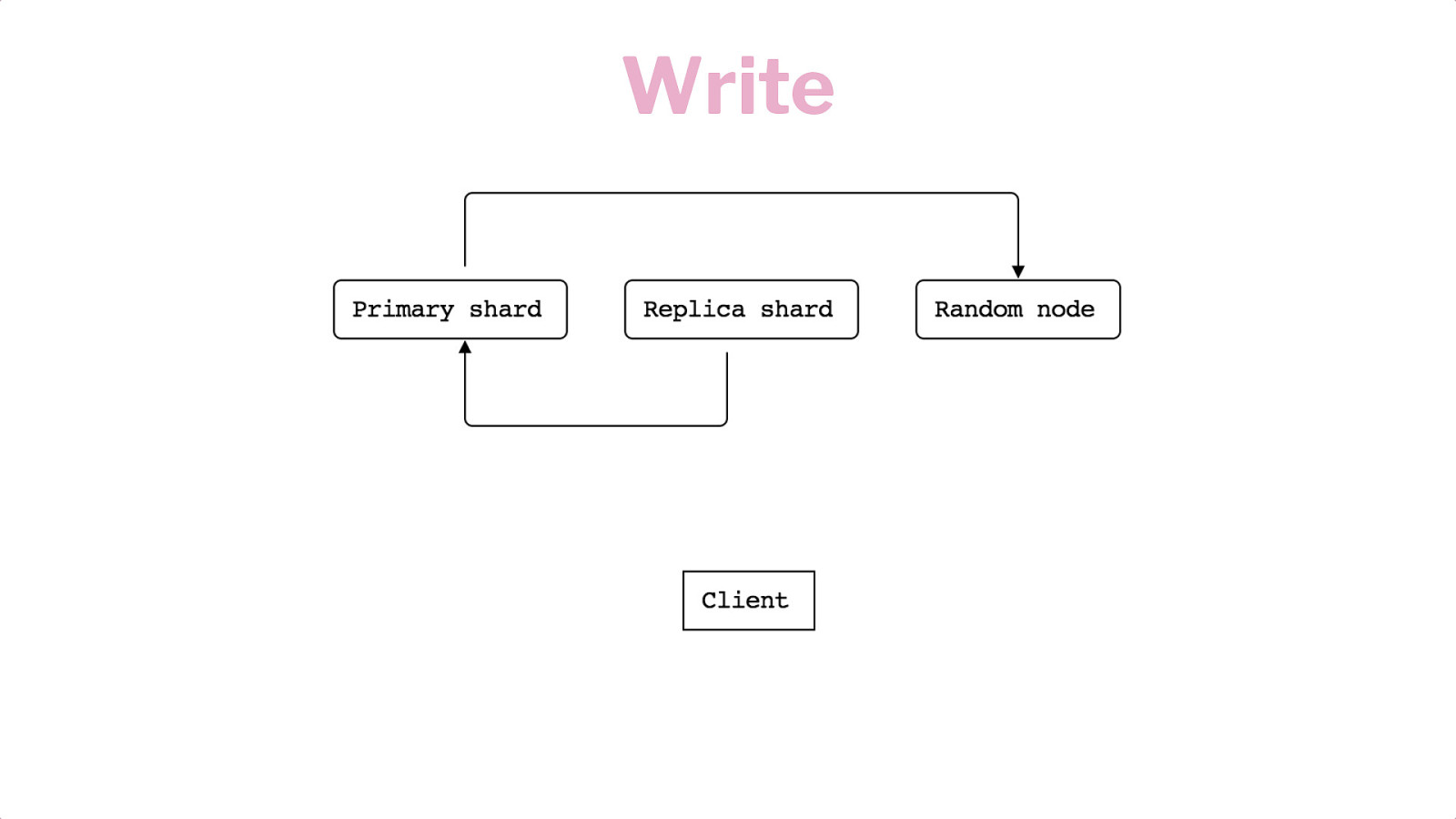
Write
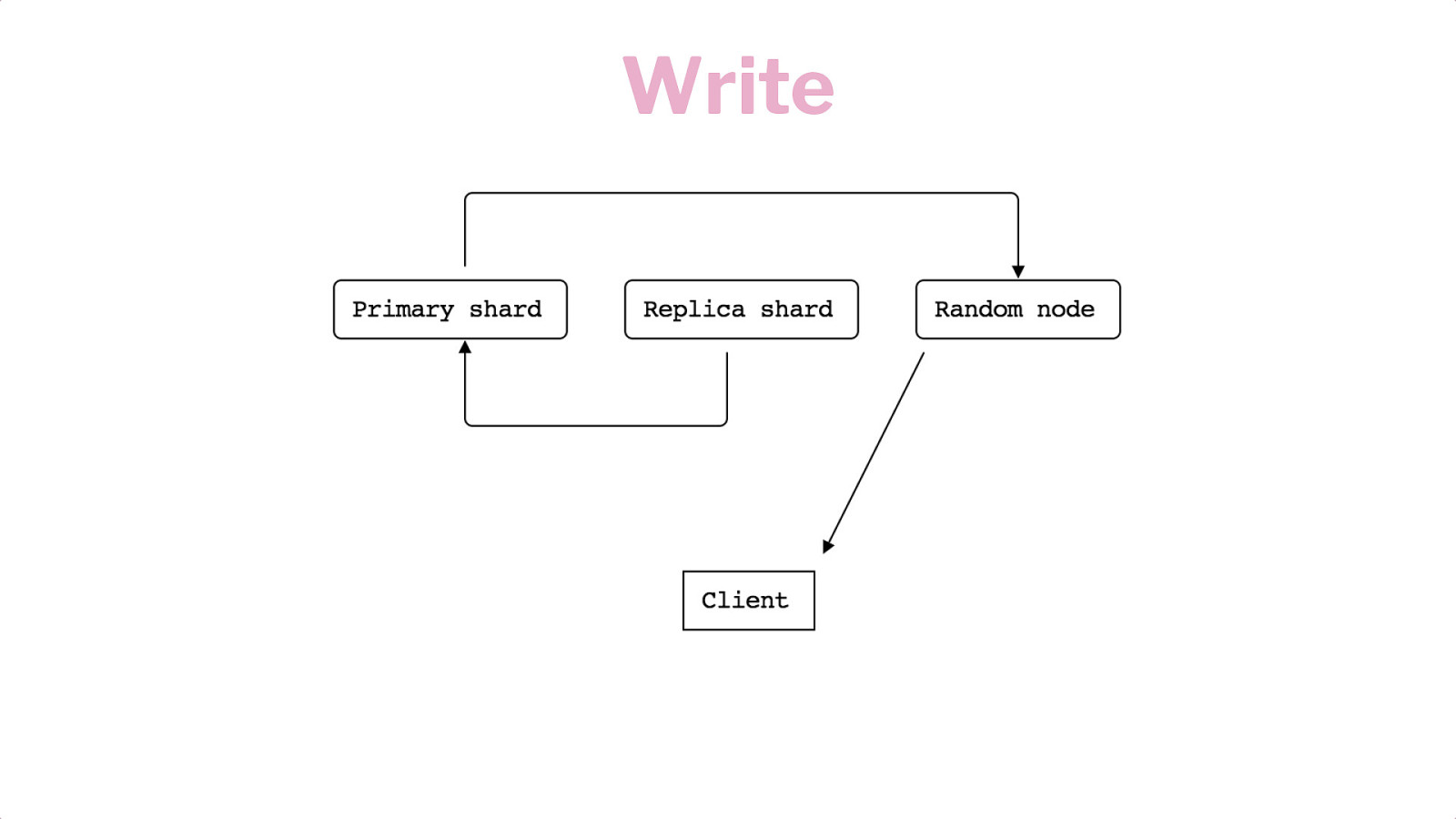
Write
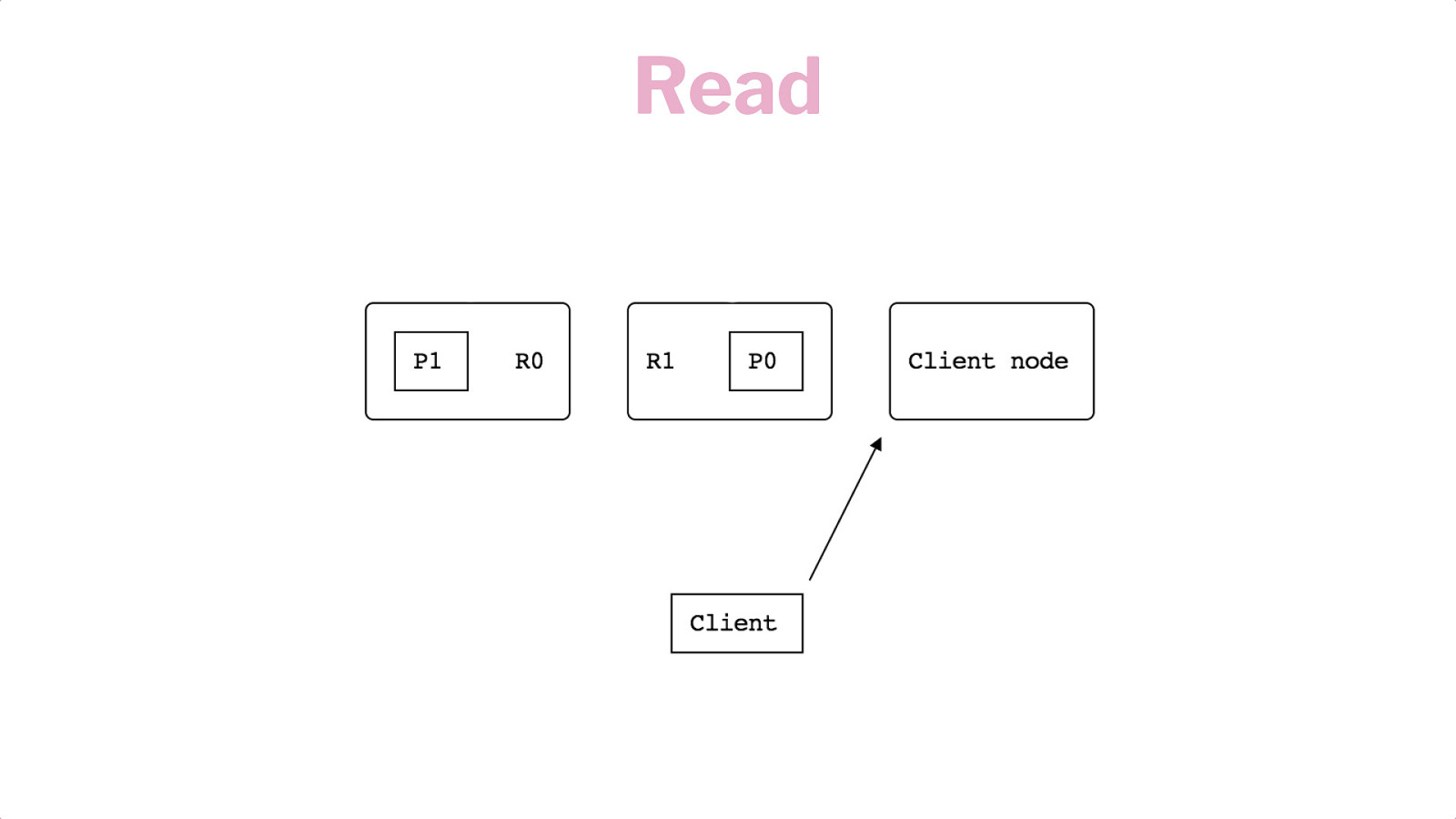
Read
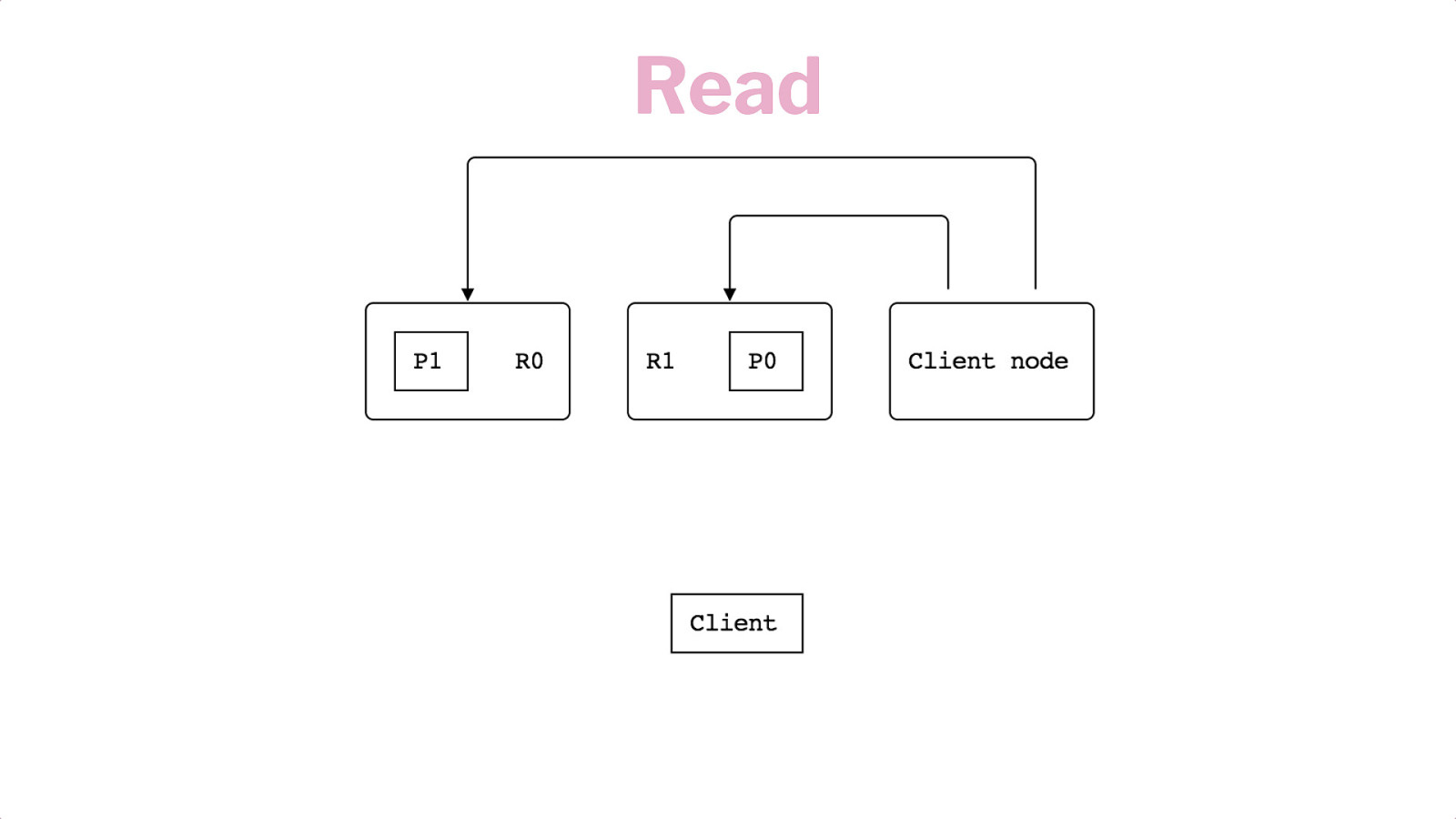
Read
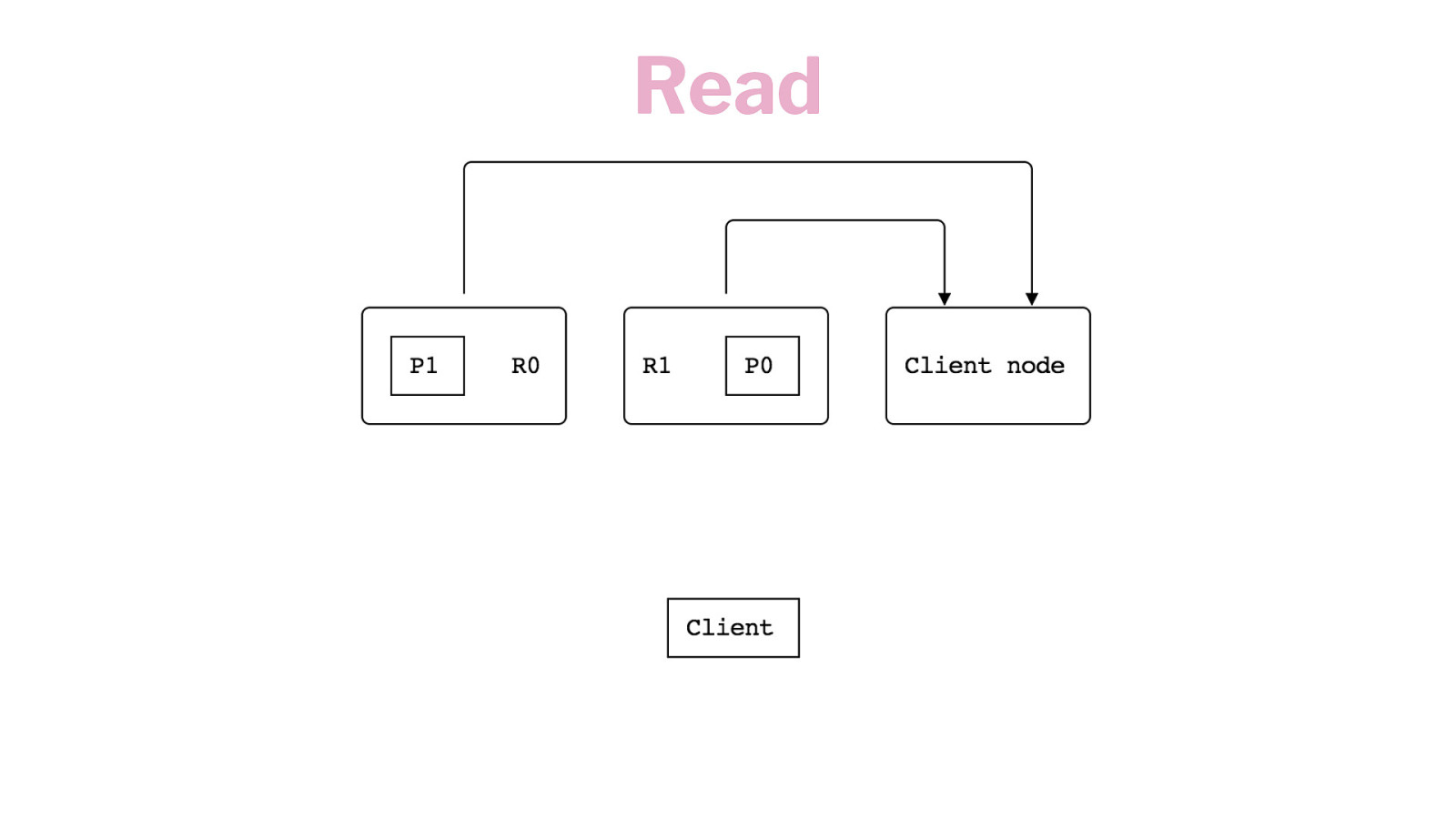
Read
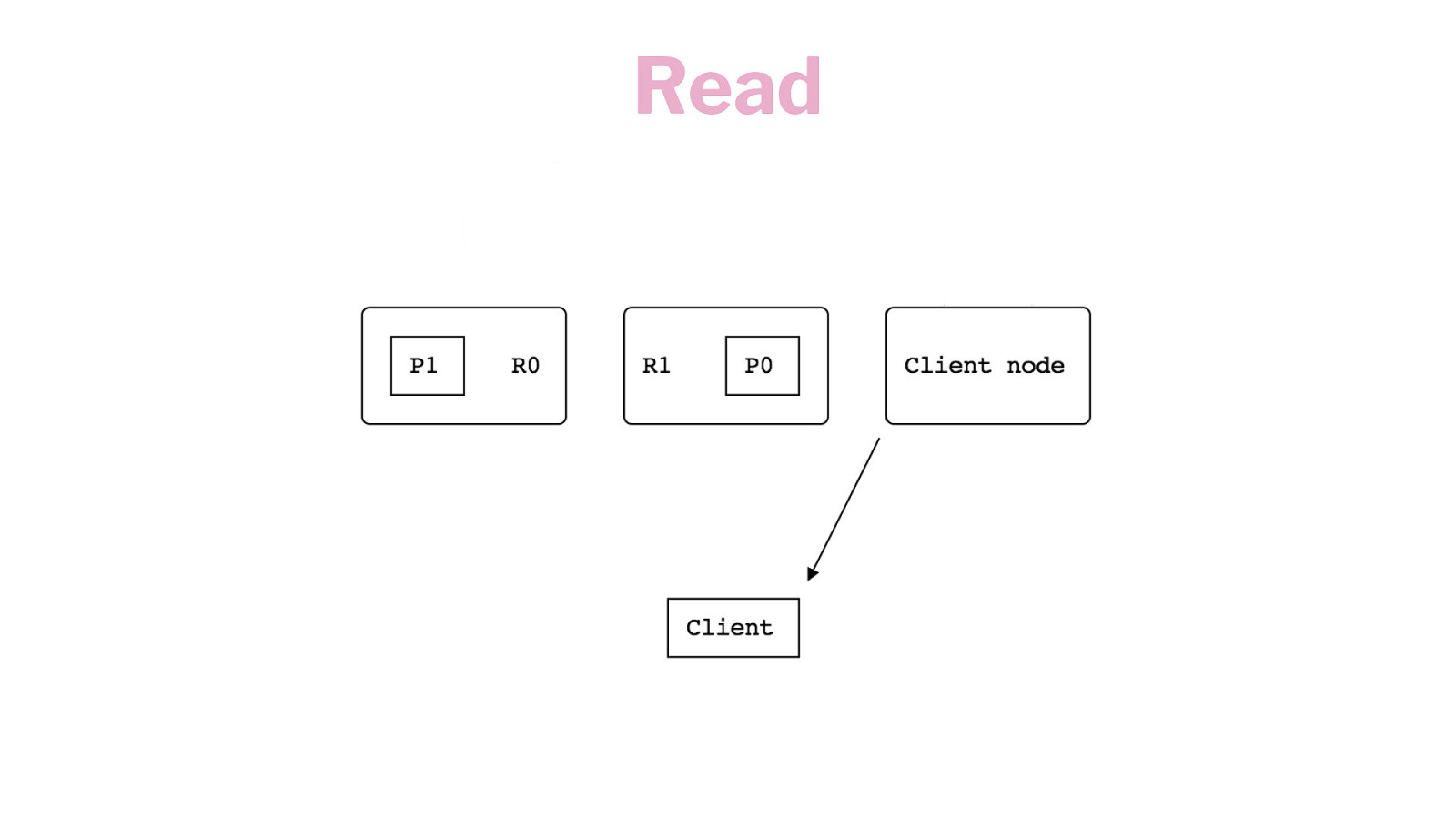
Read

Append-Only Optimization IDs assigned on coordinating node Fast add docs instead of the slow update docs

Storage Compression LZ4 (default), DEFLATE (best_compression)

BKD Trees Points in Lucene

Half & Scaled Floats

Pipeline Aggregations

Tuning

_all Removal https://www.elastic.co/guide/en/elasticsearch/ reference/current/mapping-all-field.html

Doc Values Replaced Fielddata https://www.elastic.co/guide/en/elasticsearch/ guide/current/_deep_dive_on_doc_values.html

Delivering

Architecture Hot — Warm — Cold (Frozen)
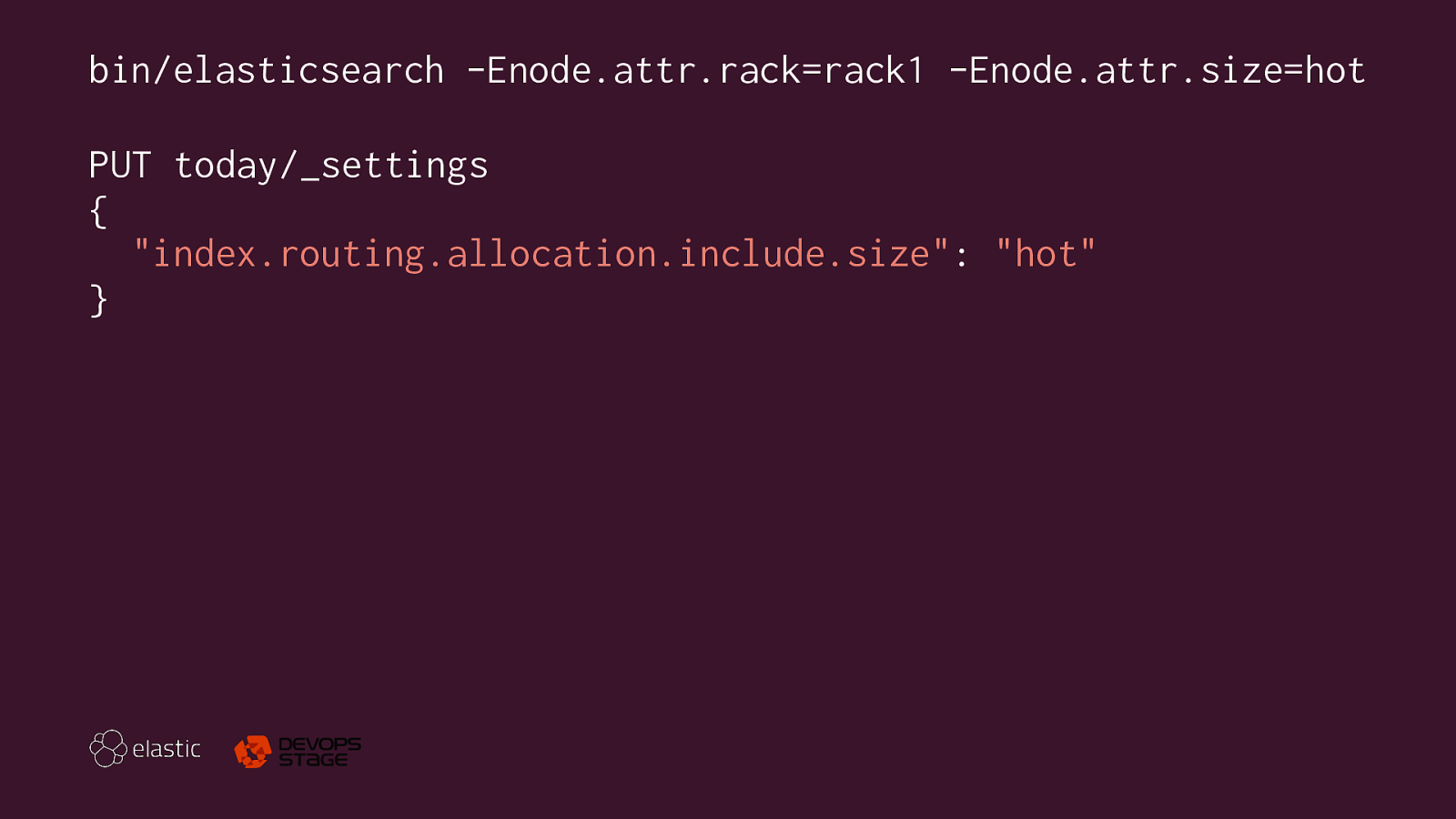
bin/elasticsearch -Enode.attr.rack=rack1 -Enode.attr.size=hot PUT today/_settings { "index.routing.allocation.include.size": "hot" }

Time-Based Indices

Rollover Indices

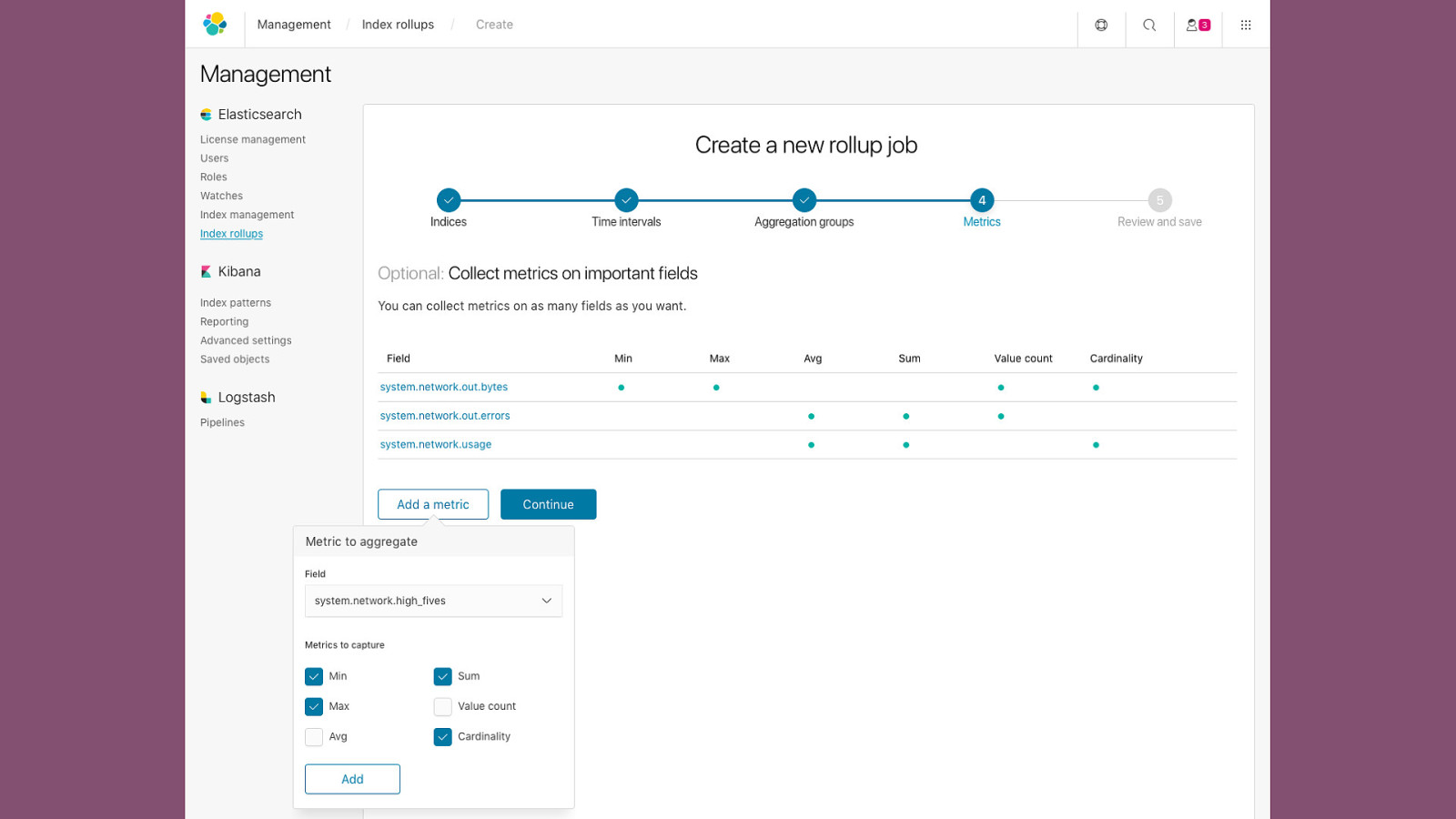
Rollups

PUT _xpack/rollup/job/metrics { "index_pattern": "metrics-", "rollup_index": "metrics_rollup", "cron": "/30 * * * * ?", "page_size" :1000, "groups" : { "date_histogram": { "field": "timestamp", "interval": "1h", "delay": "7d" }, "terms": { "fields": ["node"] } }, "metrics": [ { "field": "cpu", "metrics": ["min", "max", "sum"] }, { "field": "memory", "metrics": ["avg"] } ] }

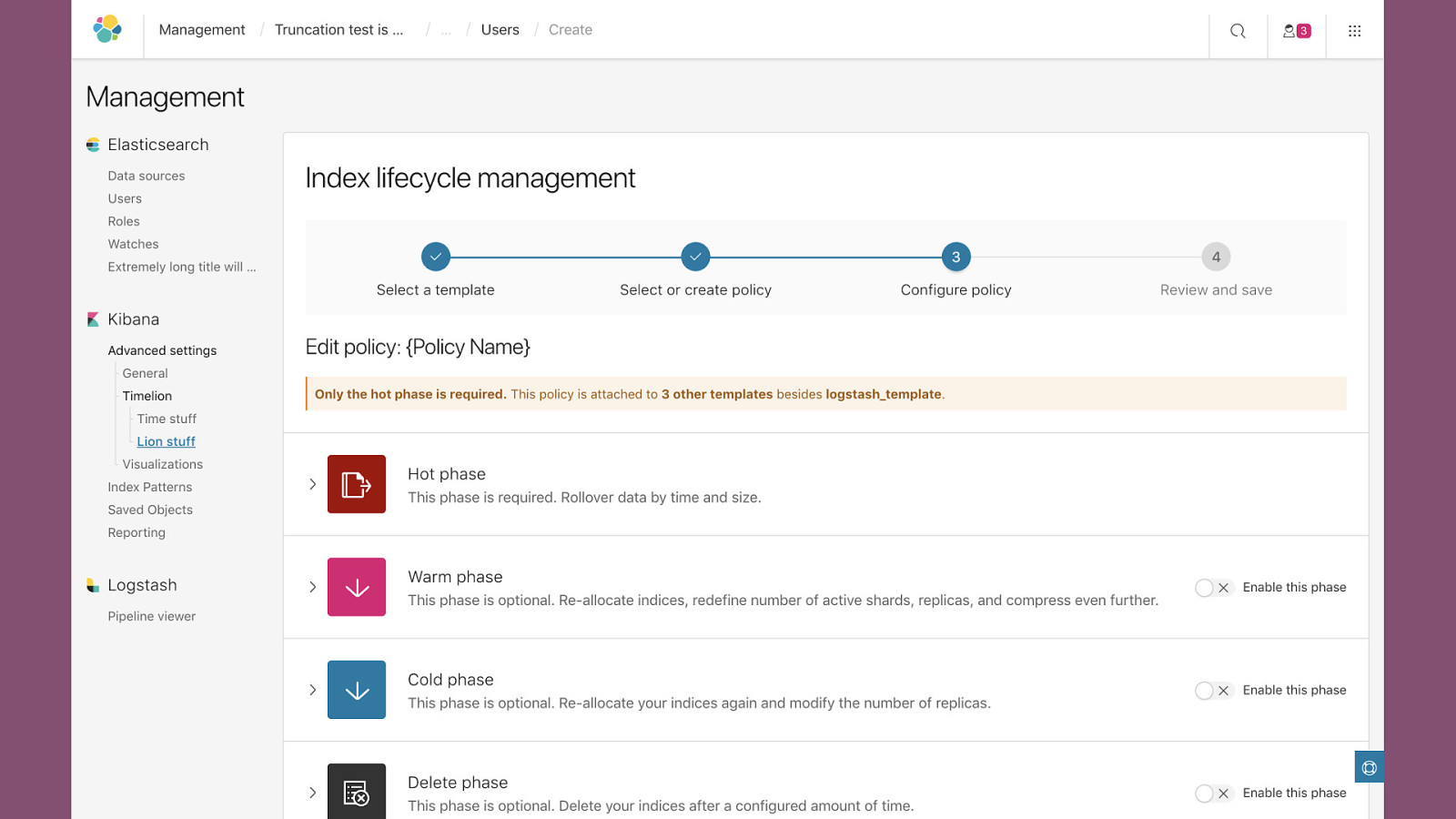
Index Lifecycle Management Currently https://github.com/elastic/curator

Conclusion

Benchmarks Fair Reproducible Close to Production




Thank You Questions? Philipp Krenn @xeraa

"Only accept features that scale" is one of Elasticsearch's engineering principles. So how do we scale metrics stored in Elasticsearch? And is that even possible on a full-text search engine? This talk explores:
- How are metrics stored in Elasticsearch and how does this translate to disk use as well as query performance?
- What does an efficient multi-tier architecture look like to balance speed for today's data against density for older metrics?
- How can you compress old data and what does the mathematical model look like for different metrics?
We are trying all of this hands-on during the talk, since this has become much simpler recently.
 for free. You
can too.
for free. You
can too.