Make Your Data FABulous
A presentation at Highload fwdays in in Kyiv, Ukraine, 02000 by Philipp Krenn


Developer

ViennaDB Papers We Love Vienna

What is the perfect datastore solution?

It depends...

Pick your tradeoffs


CAP Theorem


Consistent "[...] a total order on all operations such that each operation looks as if it were completed at a single instant."

Available "[...] every request received by a nonfailing node in the system must result in a response."

Partition Tolerant "[...] the network will be allowed to lose arbitrarily many messages sent from one node to another."
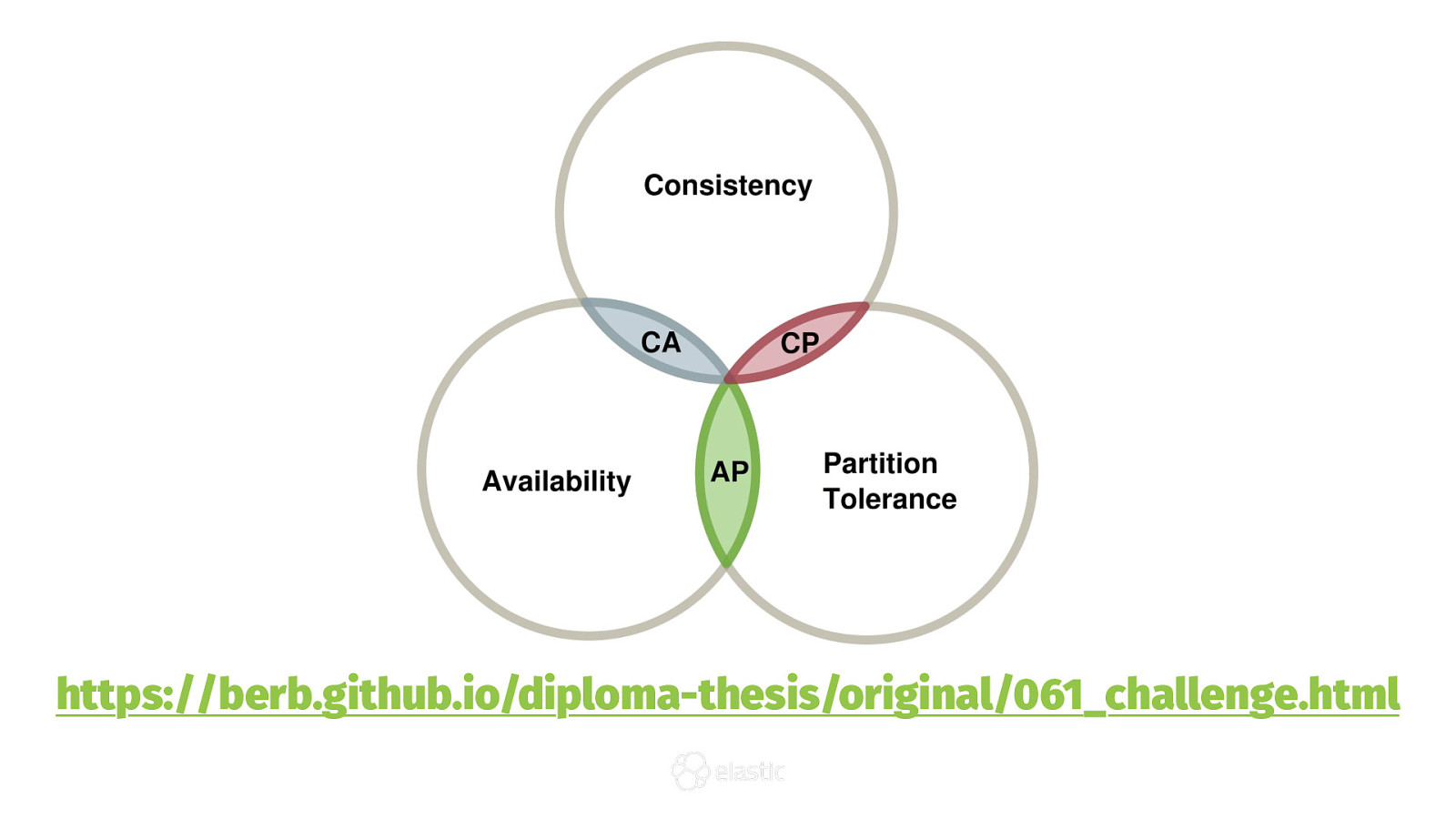
https://berb.github.io/diploma-thesis/original/061_challenge.html

Misconceptions Partition Tolerance is not a choice in a distributed system

Misconceptions Consistency in ACID is a predicate Consistency in CAP is a linear order

Robinson Crusoe


/dev/null breaks CAP: effect of write are always consistent, it's always available, and all replicas are consistent even during partitions. — https://twitter.com/ashic/status/591511683987701760

FAB Theory

Mark Harwood

Fast Near real-time instead of batch processing

Accurate Exact instead of approximate results

Big Parallelization needed to handle the data

Say Big Data one more time

Fast Big Accurate


Shard Unit of scale


"The evil wizard Mondain had attempted to gain control over Sosaria by trapping its essence in a crystal. When the Stranger at the end of Ultima I defeated Mondain and shattered the crystal, the crystal shards each held a refracted copy of Sosaria. http://www.raphkoster.com/2009/01/08/database-shardingcame-from-uo/

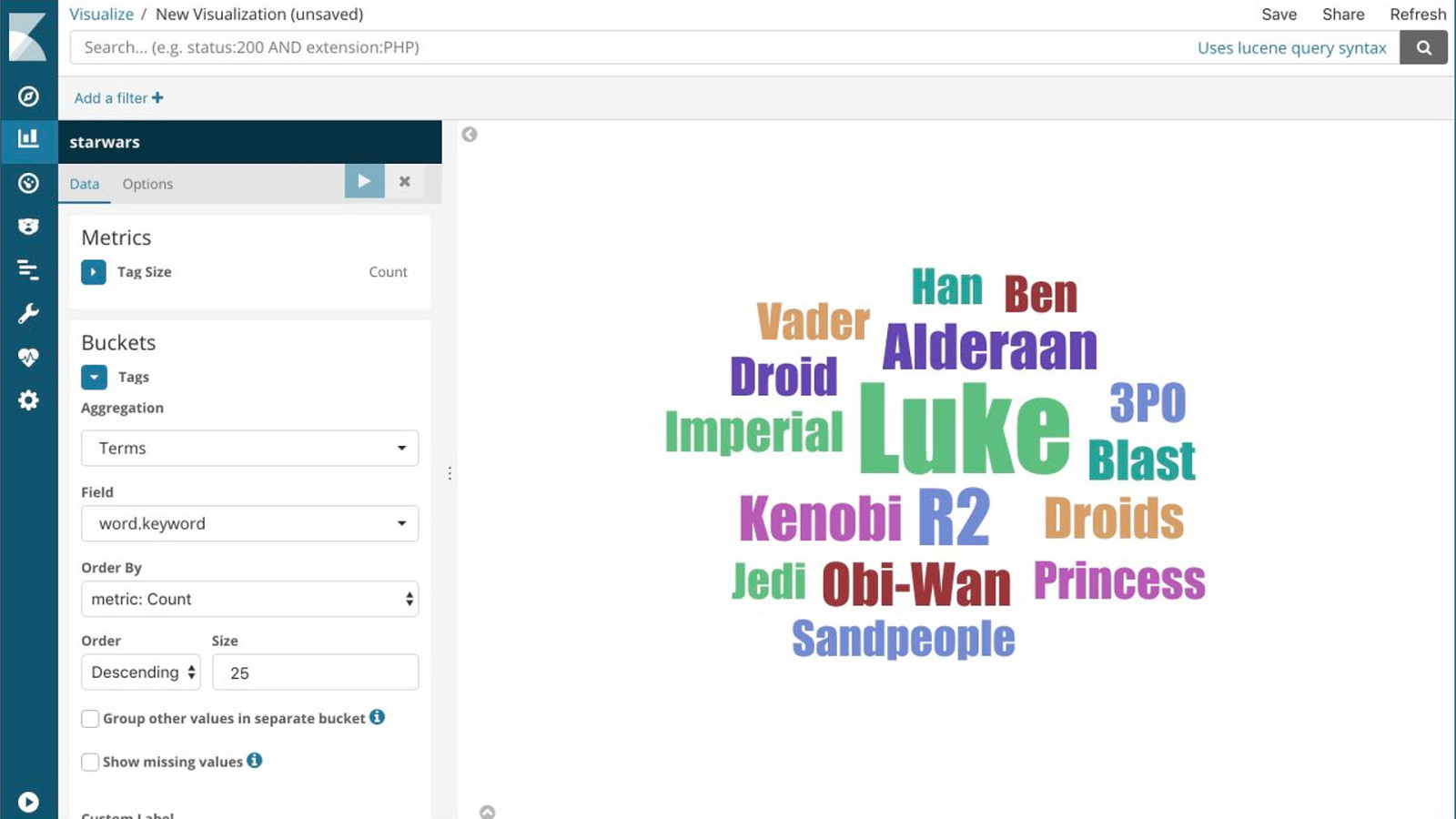
Terms Aggregation
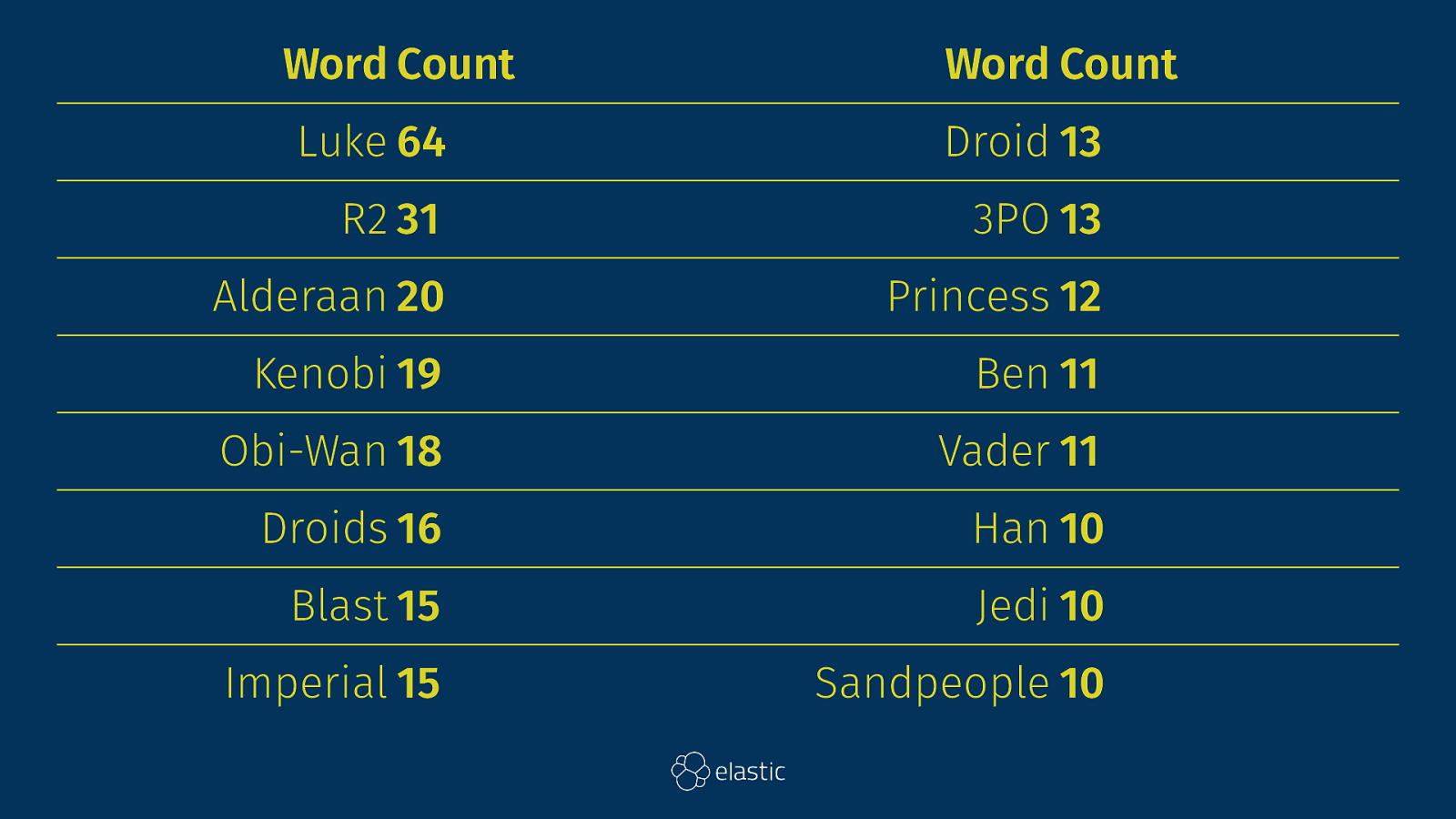
Word Count Word Count Luke 64 Droid 13 R2 31 3PO 13 Alderaan 20 Princess 12 Kenobi 19 Ben 11 Obi-Wan 18 Vader 11 Droids 16 Han 10 Blast 15 Jedi 10 Imperial 15 Sandpeople 10

PUT starwars { "settings": { "number_of_shards": 5, "number_of_replicas": 0 } }

{ "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } ... : "starwars", "_type" : "_doc", "routing": "0" } } : "starwars", "_type" : "_doc", "routing": "1" } } : "starwars", "_type" : "_doc", "routing": "2" } } : "starwars", "_type" : "_doc", "routing": "3" } }

GET starwars/_search { "query": { "match": { "word": "Luke" } } }
{ "took": 6, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 64, "max_score": 3.2049506, "hits": [ { "_index": "starwars", "_type": "_doc", "_id": "0vVdy2IBkmPuaFRg659y", "_score": 3.2049506, "_routing": "1", "_source": { "word": "Luke" } }, ...
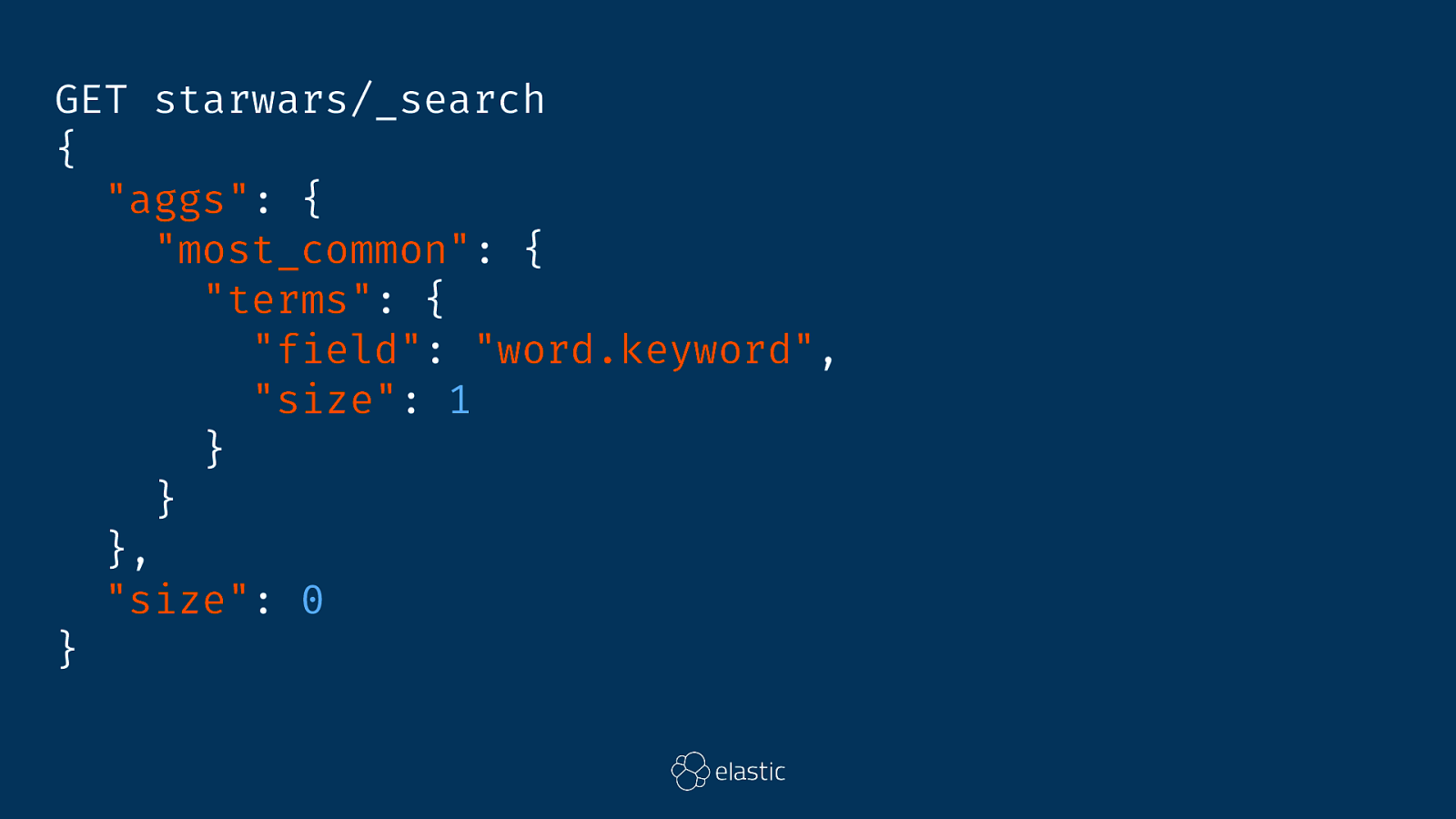
GET starwars/_search { "aggs": { "most_common": { "terms": { "field": "word.keyword", "size": 1 } } }, "size": 0 }
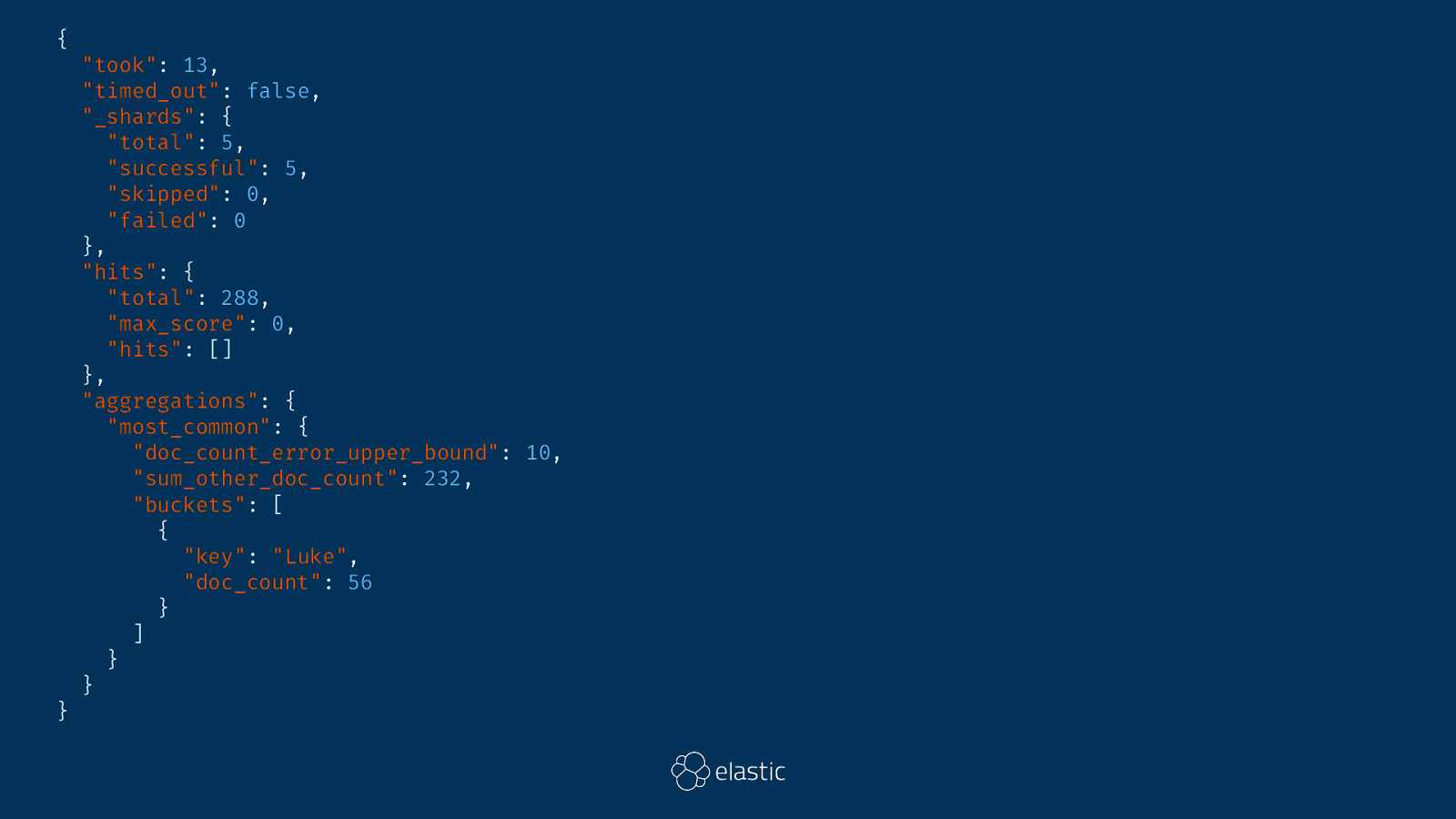
{ } "took": 13, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 288, "max_score": 0, "hits": [] }, "aggregations": { "most_common": { "doc_count_error_upper_bound": 10, "sum_other_doc_count": 232, "buckets": [ { "key": "Luke", "doc_count": 56 } ] } }


{ "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } ... { "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } { "index" : { "_index" { "word" : "Luke" } ... : "starwars", "_type" : "_doc", "routing": "0" } } : "starwars", "_type" : "_doc", "routing": "1" } } : "starwars", "_type" : "_doc", "routing": "2" } } : "starwars", "_type" : "_doc", "routing": "8" } } : "starwars", "_type" : "_doc", "routing": "9" } } : "starwars", "_type" : "_doc", "routing": "0" } } : "starwars", "_type" : "_doc", "routing": "0" } }

Routing shard# = hash(_routing) % #primary_shards
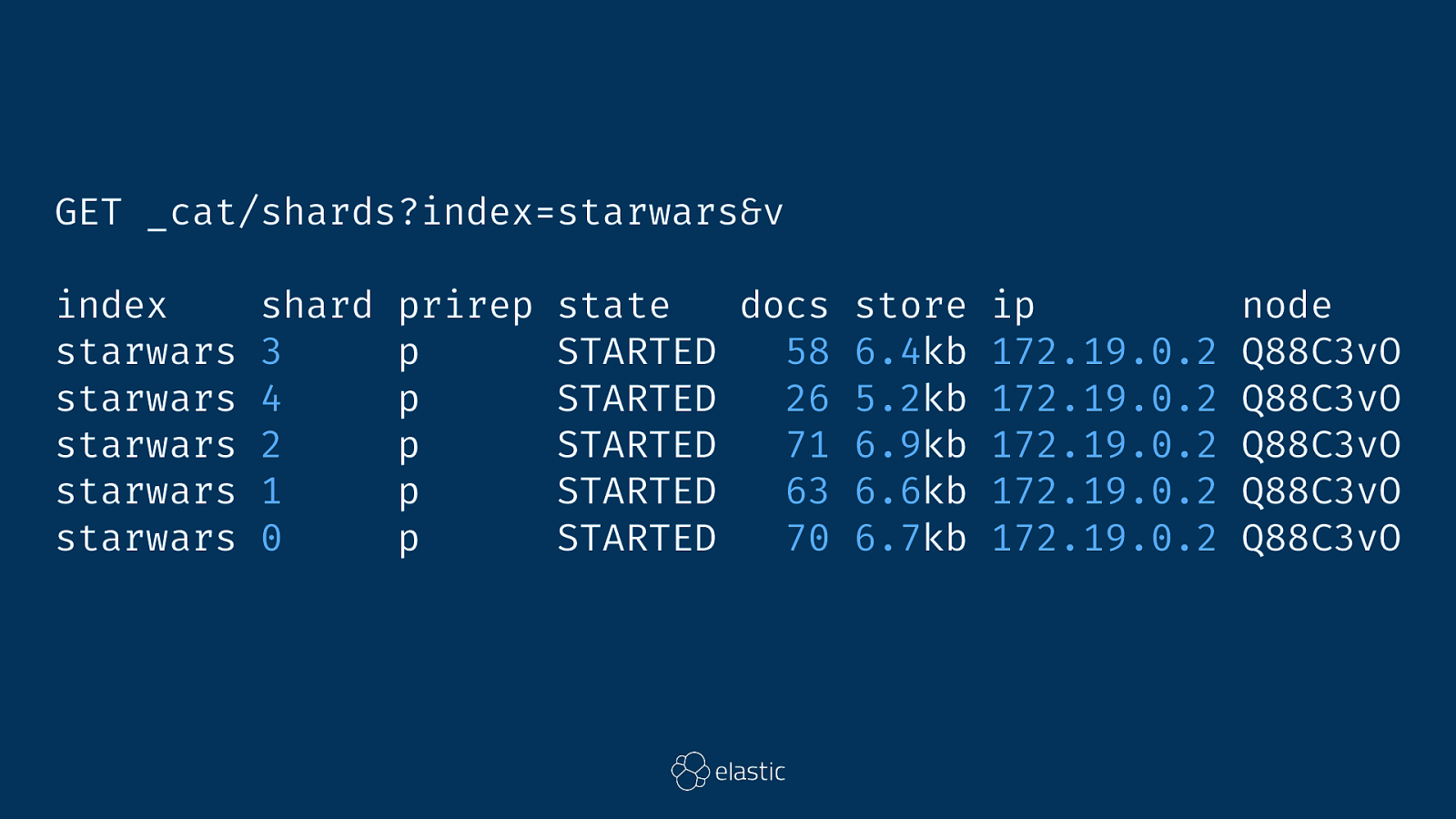
GET _cat/shards?index=starwars&v index starwars starwars starwars starwars starwars shard 3 4 2 1 0 prirep p p p p p state docs store ip node STARTED 58 6.4kb 172.19.0.2 Q88C3vO STARTED 26 5.2kb 172.19.0.2 Q88C3vO STARTED 71 6.9kb 172.19.0.2 Q88C3vO STARTED 63 6.6kb 172.19.0.2 Q88C3vO STARTED 70 6.7kb 172.19.0.2 Q88C3vO

(Sub) Results Per Shard shard_size = (size * 1.5 + 10)

How Many? Results per shard Results for aggregation
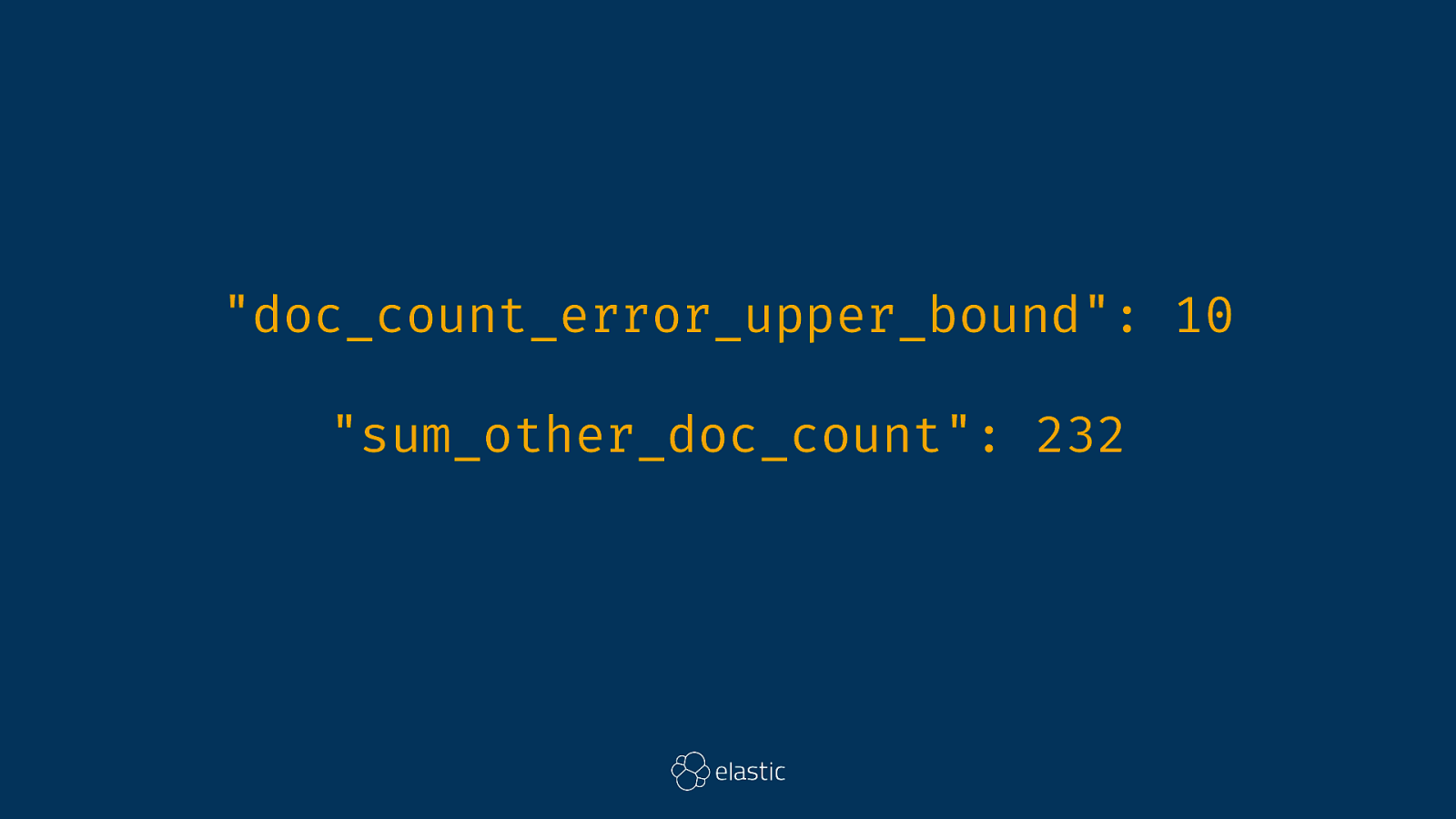
"doc_count_error_upper_bound": 10 "sum_other_doc_count": 232
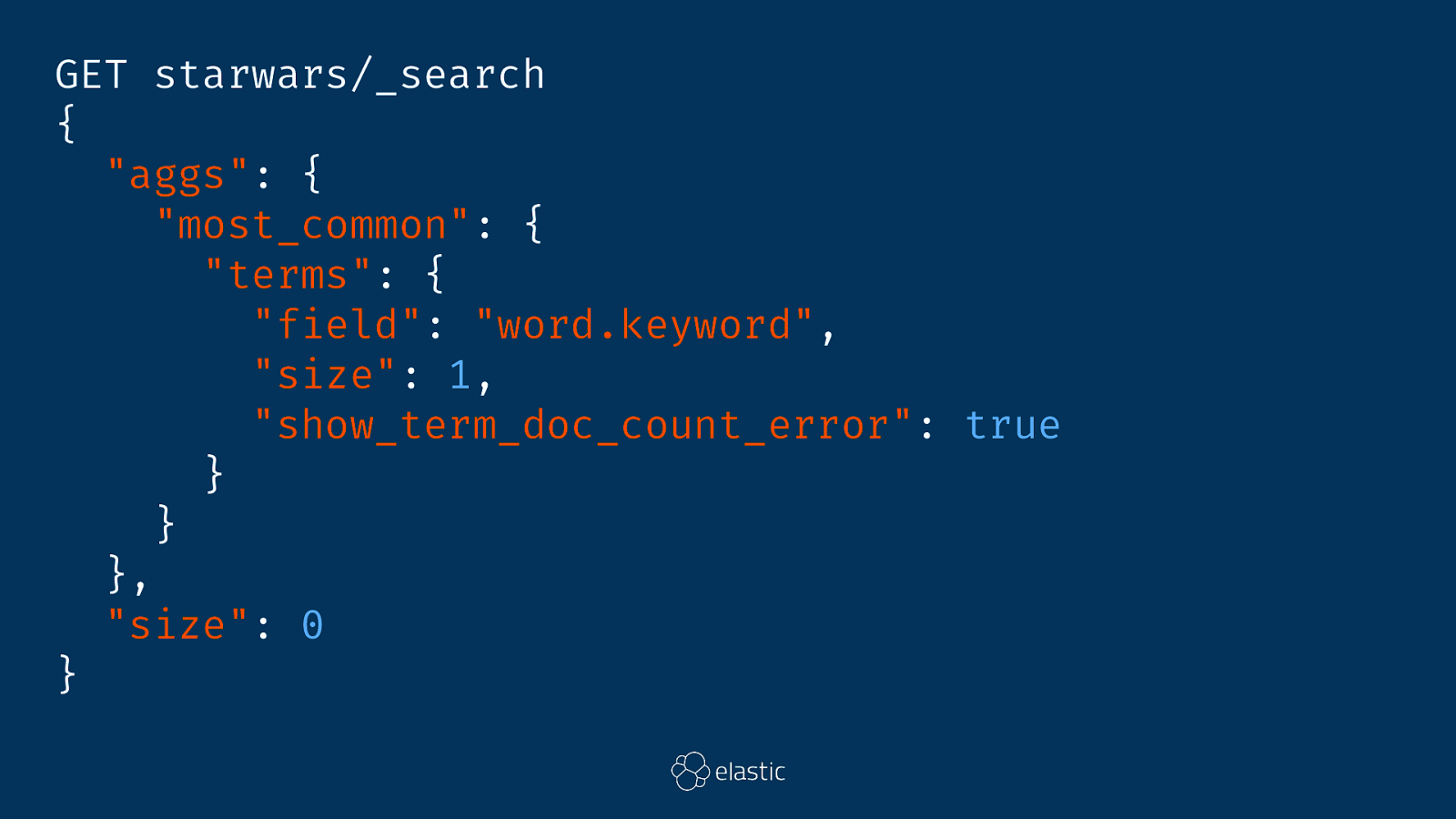
GET starwars/_search { "aggs": { "most_common": { "terms": { "field": "word.keyword", "size": 1, "show_term_doc_count_error": true } } }, "size": 0 }

"aggregations": { "most_common": { "doc_count_error_upper_bound": 10, "sum_other_doc_count": 232, "buckets": [ { "key": "Luke", "doc_count": 56, "doc_count_error_upper_bound": 9 } ] } }
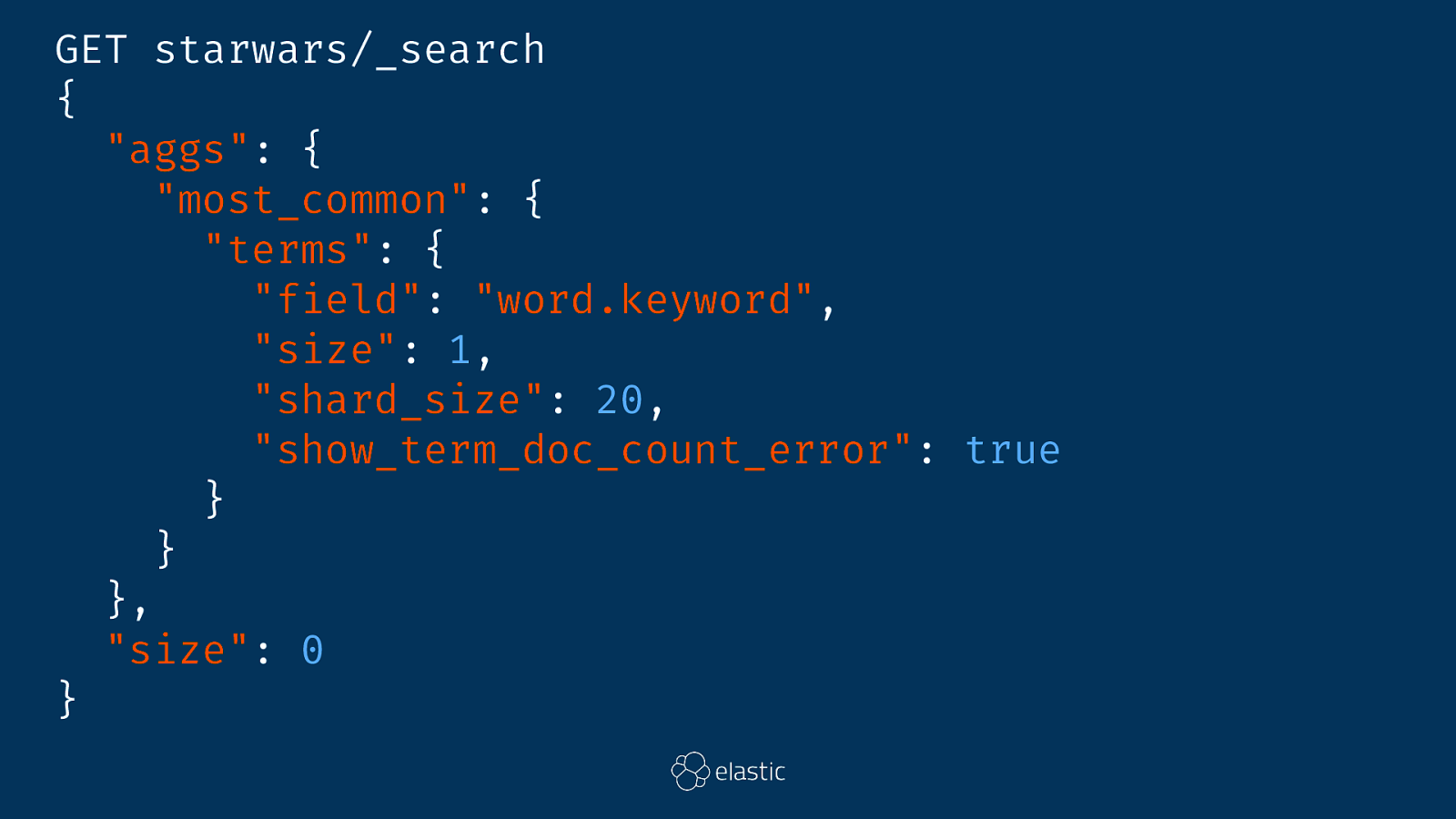
GET starwars/_search { "aggs": { "most_common": { "terms": { "field": "word.keyword", "size": 1, "shard_size": 20, "show_term_doc_count_error": true } } }, "size": 0 }

"aggregations": { "most_common": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 224, "buckets": [ { "key": "Luke", "doc_count": 64, "doc_count_error_upper_bound": 0 } ] } }

Cardinality Aggregation

Naive implementation: Hash set Predictable storage and performance?


[...] the maximum number of leading zeros that occur for all hash values, where intuitively hash values with more leading zeros are less likely and indicate a larger cardinality.

If the bit pattern is observed at the beginning of a hash value, then a good estimation of the size of the multiset is [...].

To reduce the large variability that such a single measurement has, a technique known as stochastic averaging is used.


GET starwars/_search { "aggs": { "type_count": { "cardinality": { "field": "word.keyword", "precision_threshold": 10 } } }, "size": 0 }

{ } "took": 3, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 288, "max_score": 0, "hits": [] }, "aggregations": { "type_count": { "value": 17 } }

precision_threshold Default 3,000 Maximum 40,000

Memory precision_threshold x 8 bytes

GET starwars/_search { "aggs": { "type_count": { "cardinality": { "field": "word.keyword", "precision_threshold": 12 } } }, "size": 0 }

{ } "took": 12, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 288, "max_score": 0, "hits": [] }, "aggregations": { "type_count": { "value": 16 } }

Precompute Hashes? Client or mapper-murmur3 plugin

It Depends ! large / high-cardinality fields ! low cardinality / numeric fields

Improvement: LogLog-β https://github.com/elastic/elasticsearch/ pull/22323

Improvement? "New cardinality estimation algorithms for HyperLogLog sketches" https://arxiv.org/abs/1702.01284

Inverse Document Frequency

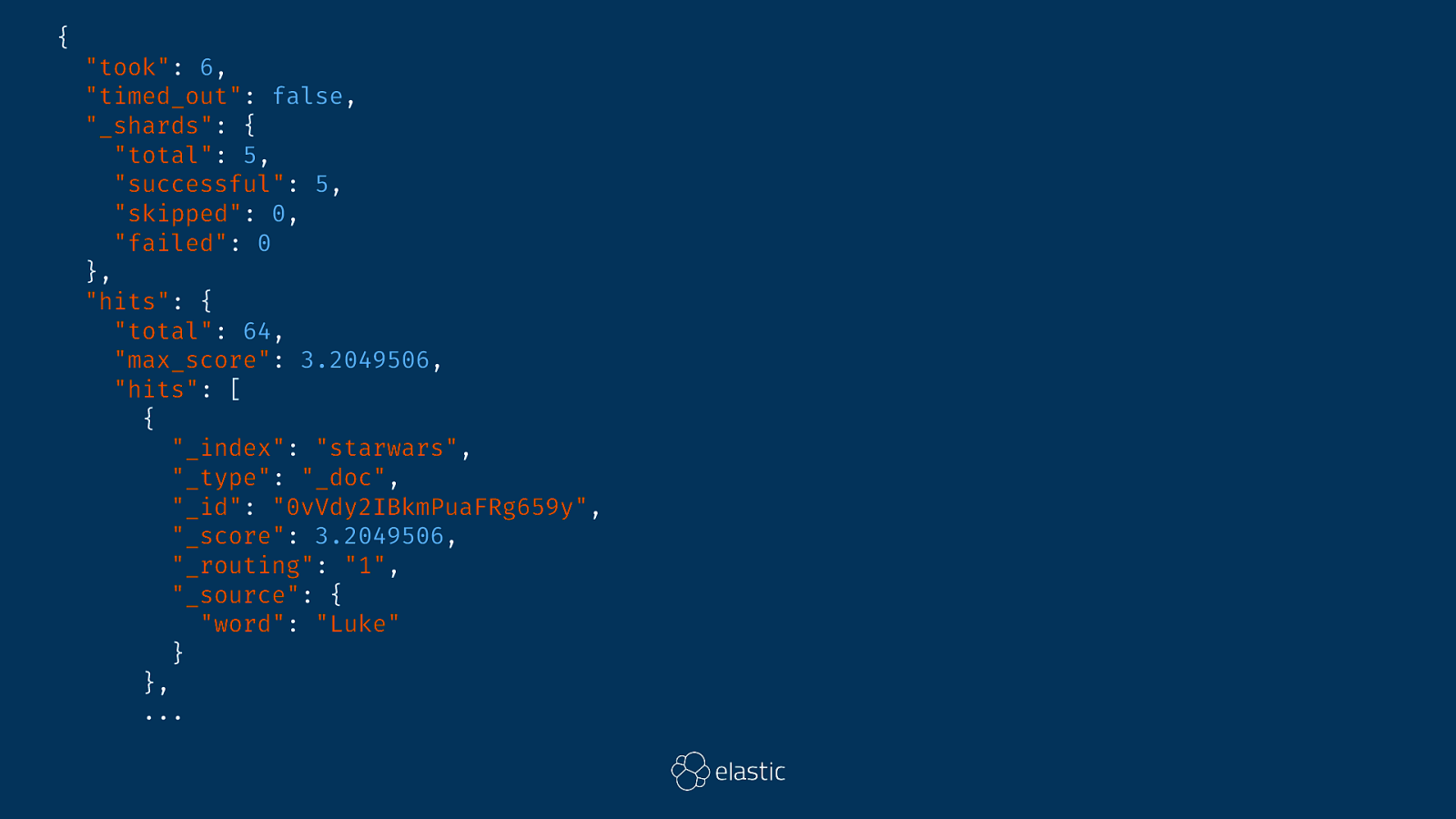
GET starwars/_search { "query": { "match": { "word": "Luke" } } }

... { "_index": "starwars", "_type": "_doc", "_id": "0vVdy2IBkmPuaFRg659y", "_score": 3.2049506, "_routing": "1", "_source": { "word": "Luke" } }, { "_index": "starwars", "_type": "_doc", "_id": "2PVdy2IBkmPuaFRg659y", "_score": 3.2049506, "_routing": "7", "_source": { "word": "Luke" } }, { "_index": "starwars", "_type": "_doc", "_id": "0_Vdy2IBkmPuaFRg659y", "_score": 3.1994843, "_routing": "2", "_source": { "word": "Luke" } }, ...


Term Frequency / Inverse Document Frequency (TF/IDF)

BM25 Default in Elasticsearch 5.0

Term Frequency
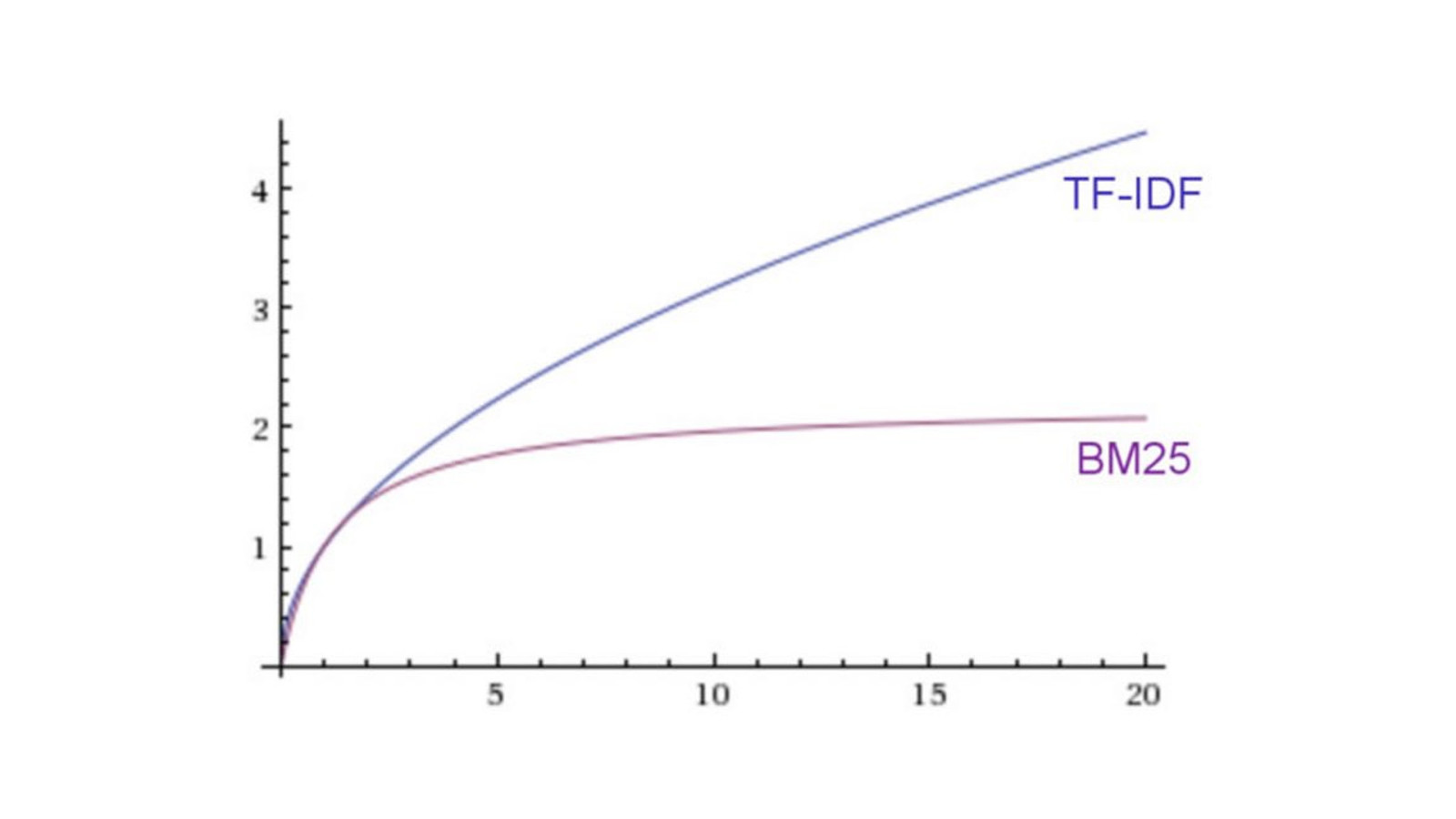

Inverse Document Frequency
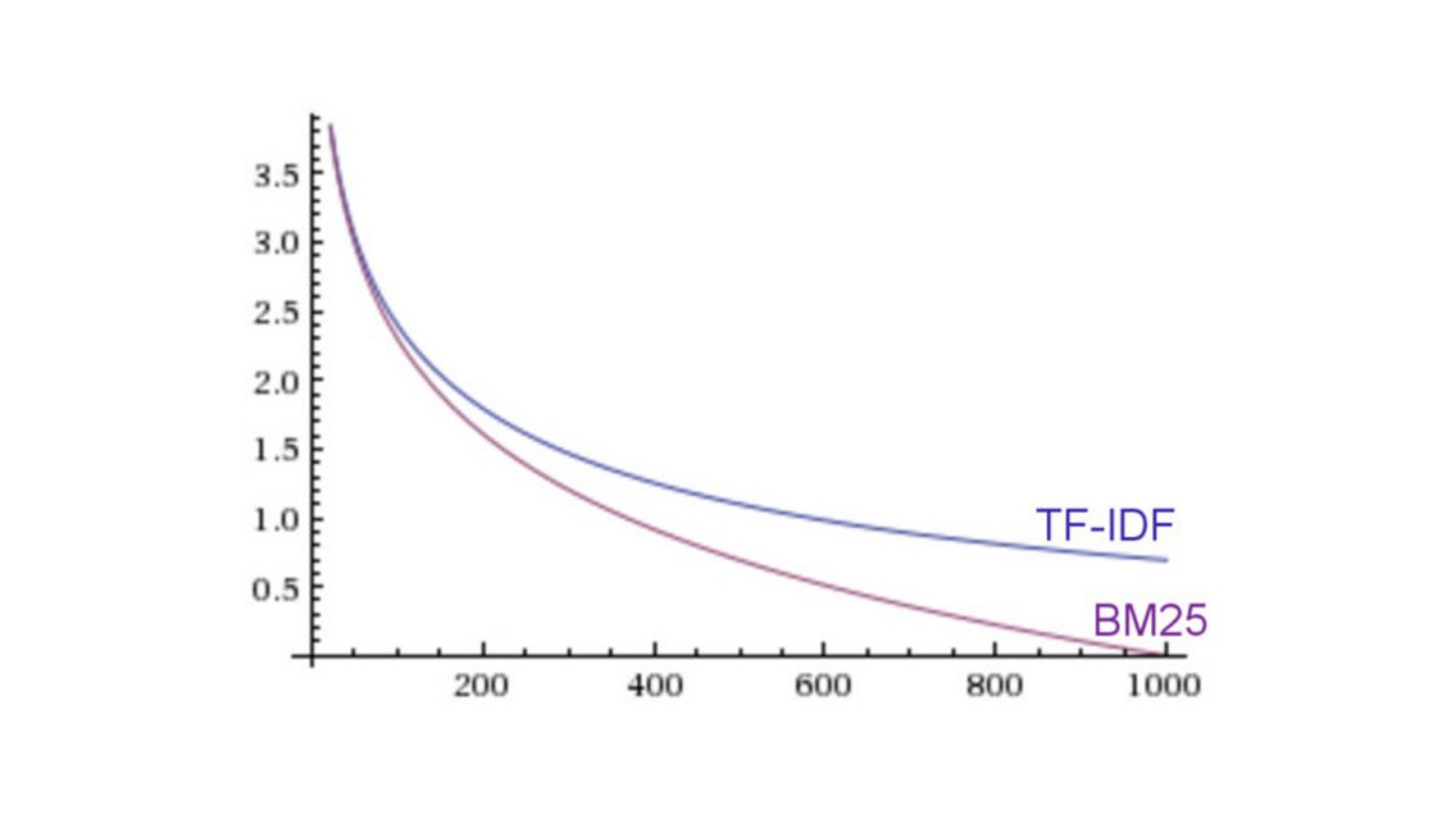

Field-Length Norm

Query Then Fetch
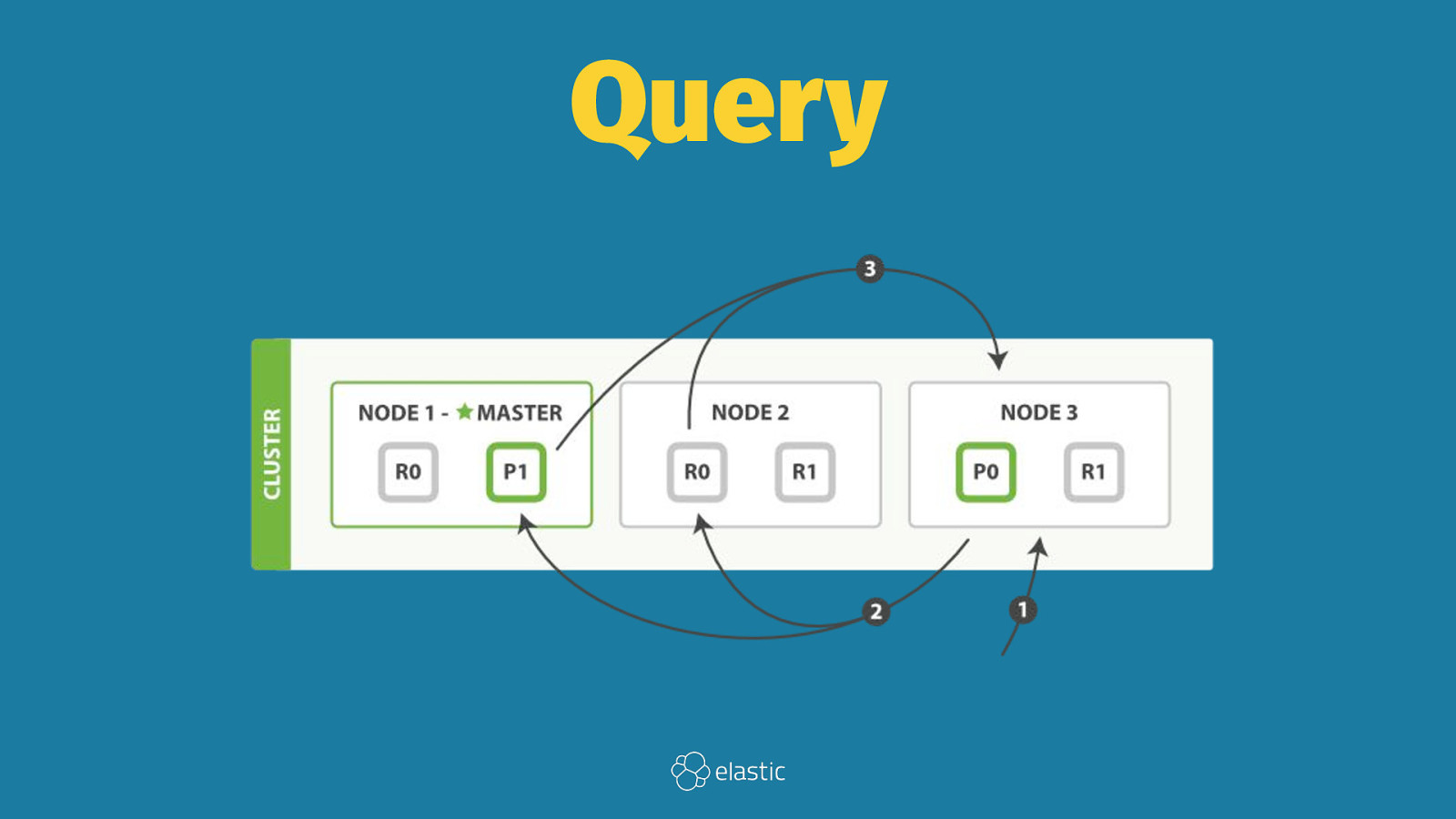
Query
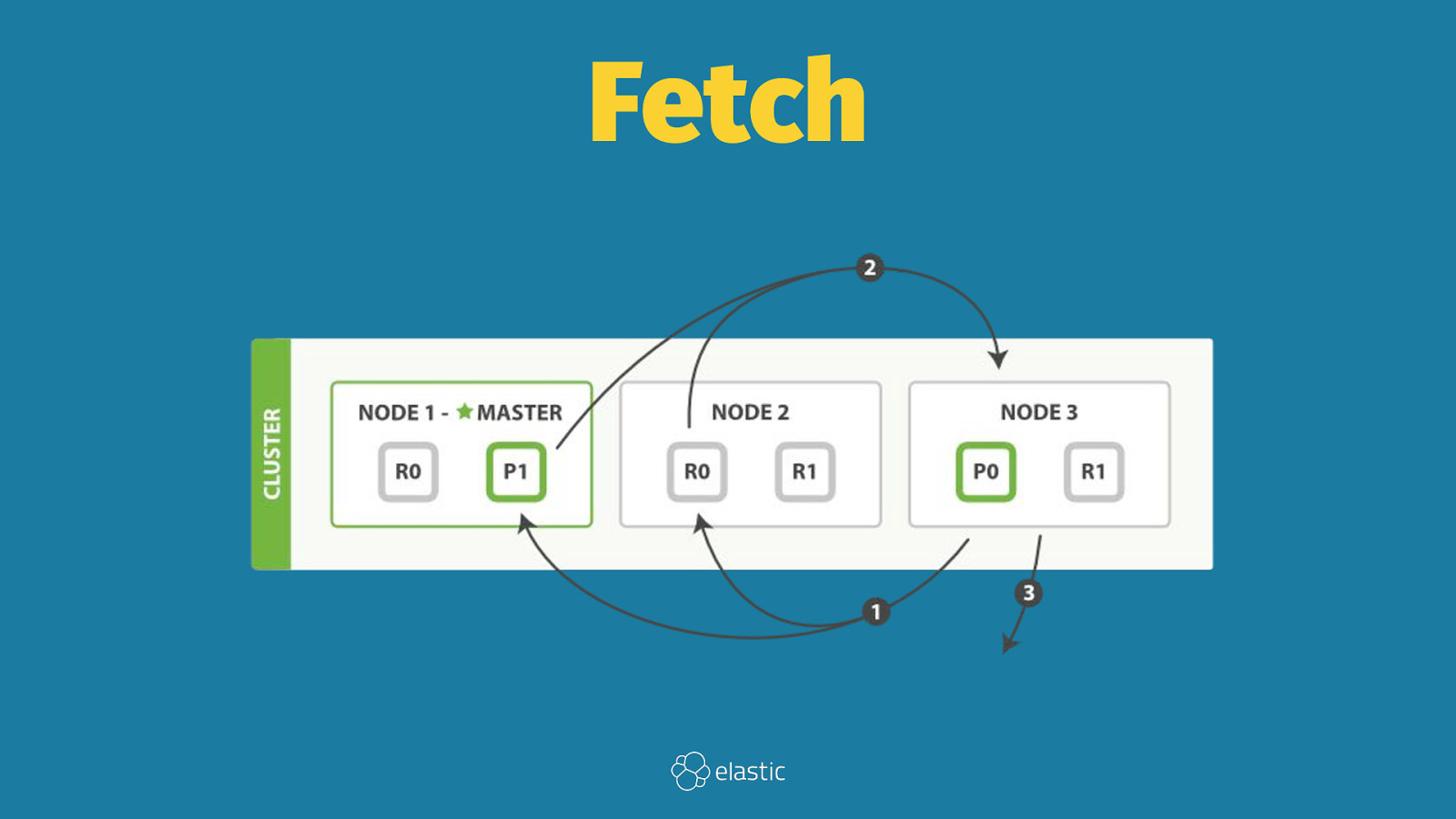
Fetch

DFS Query Then Fetch Distributed Frequency Search
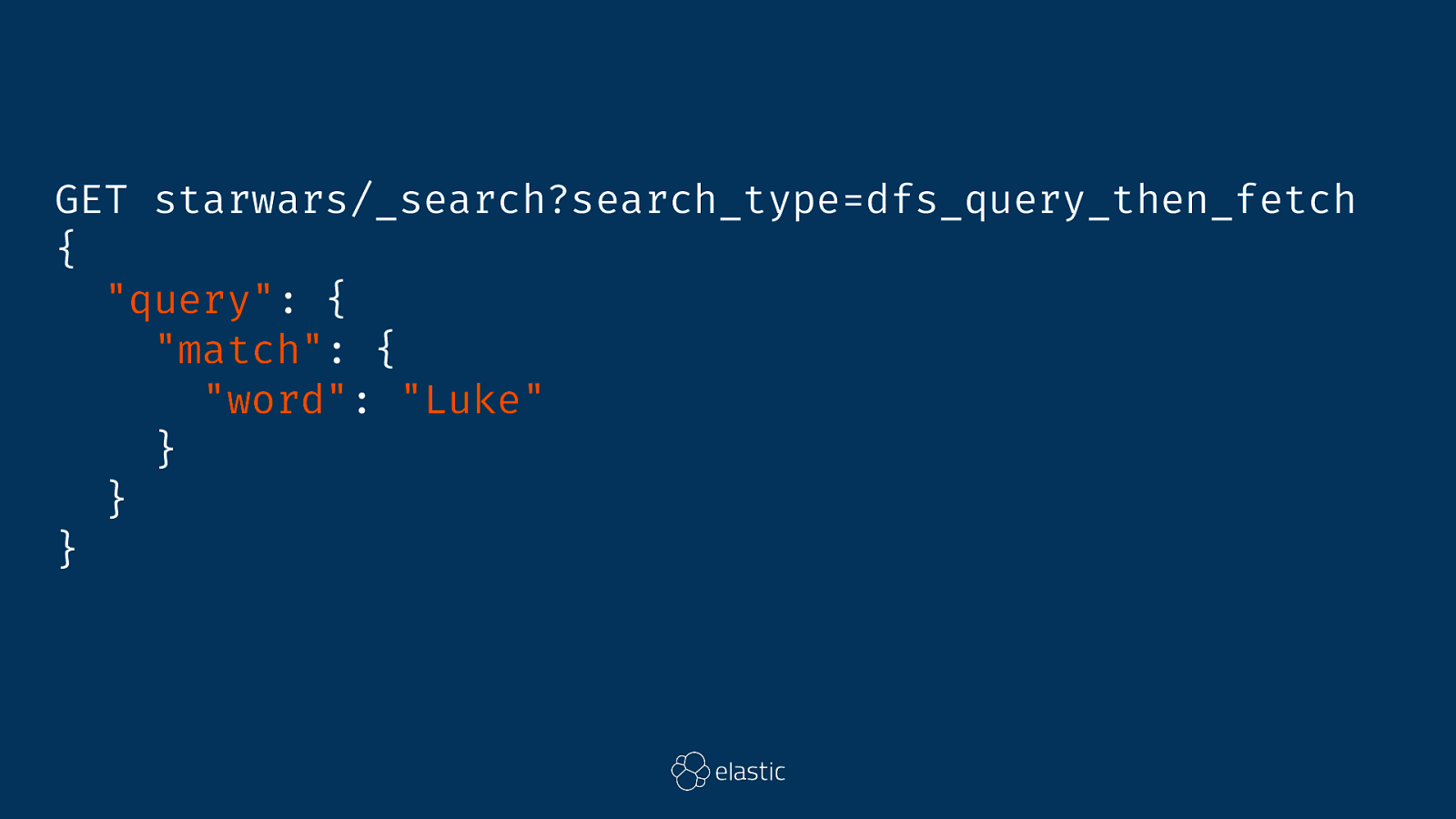
GET starwars/_search?search_type=dfs_query_then_fetch { "query": { "match": { "word": "Luke" } } }

{ "_index": "starwars", "_type": "_doc", "_id": "0fVdy2IBkmPuaFRg659y", "_score": 1.5367417, "_routing": "0", "_source": { "word": "Luke" } }, { "_index": "starwars", "_type": "_doc", "_id": "2_Vdy2IBkmPuaFRg659y", "_score": 1.5367417, "_routing": "0", "_source": { "word": "Luke" } }, { "_index": "starwars", "_type": "_doc", "_id": "3PVdy2IBkmPuaFRg659y", "_score": 1.5367417, "_routing": "0", "_source": { "word": "Luke" } }, ...



Don’t use dfs_query_then_fetch in production. It really isn’t required. — https://www.elastic.co/guide/en/elasticsearch/ guide/current/relevance-is-broken.html

Single Shard Default in 7.0

Simon Says Use a single shard until it blows up

PUT starwars/_settings { "settings": { "index.blocks.write": true } }
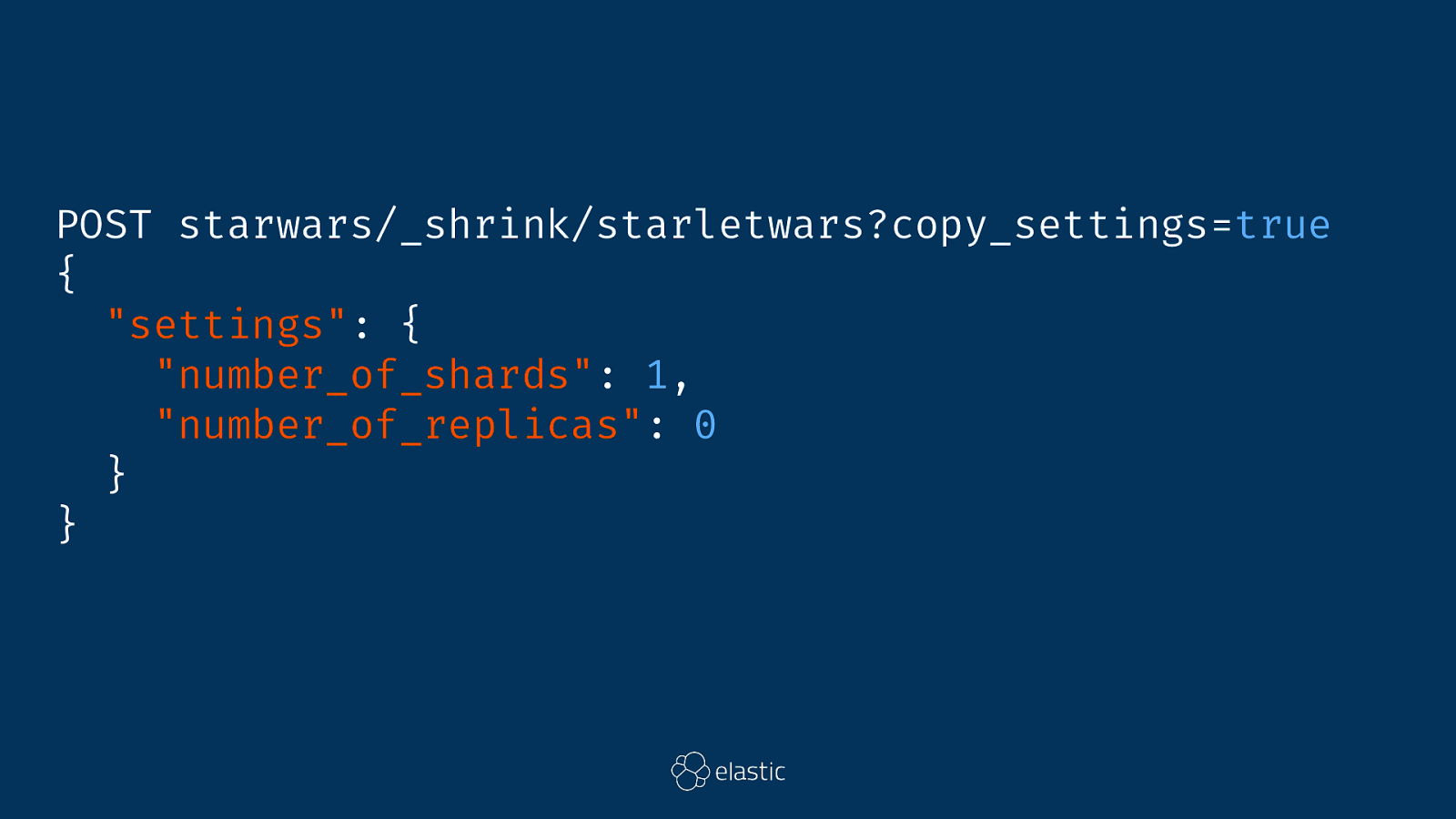
POST starwars/_shrink/starletwars?copy_settings=true { "settings": { "number_of_shards": 1, "number_of_replicas": 0 } }

GET starletwars/_search { "query": { "match": { "word": "Luke" } }, "_source": false }
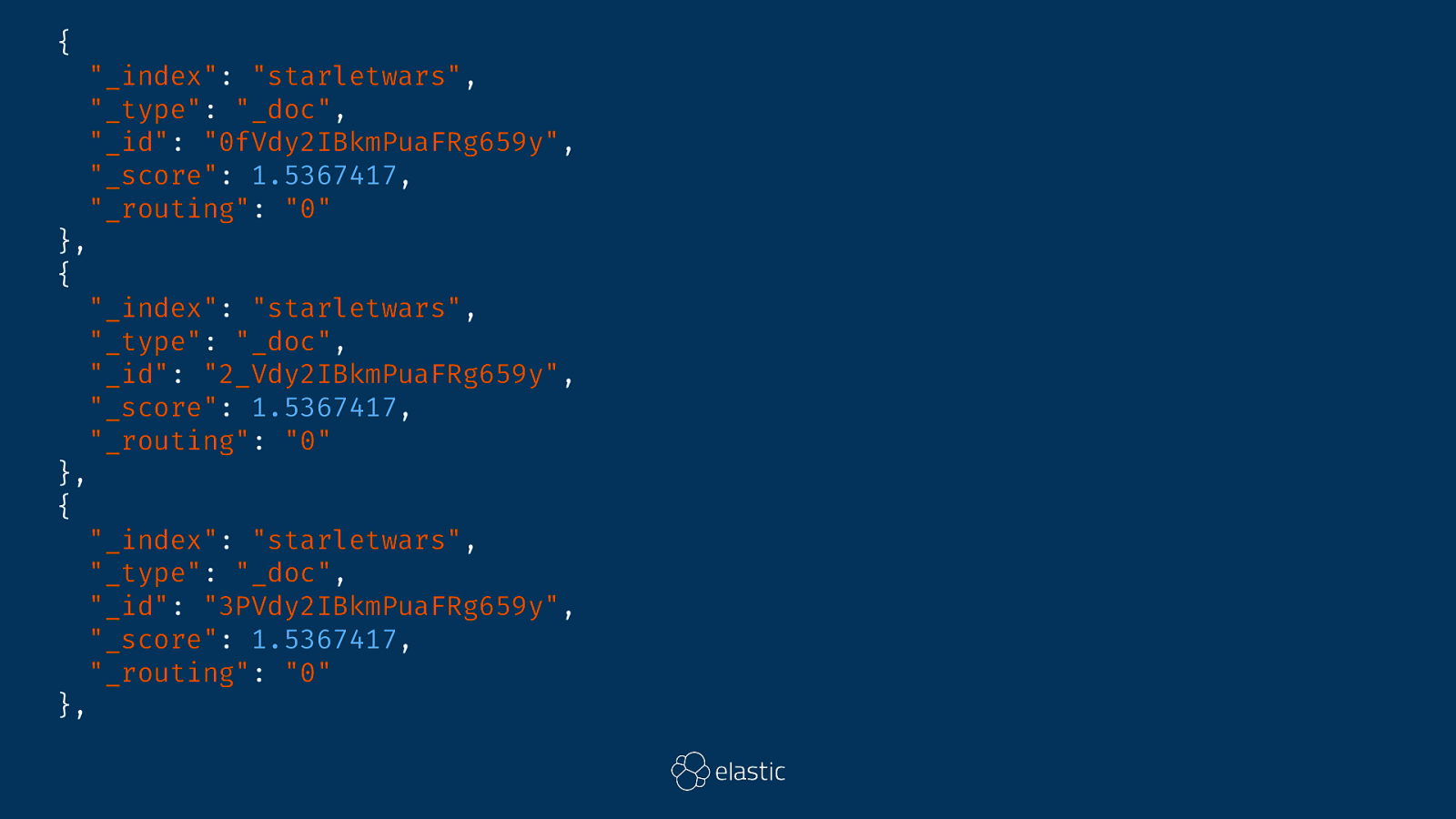
{ "_index": "starletwars", "_type": "_doc", "_id": "0fVdy2IBkmPuaFRg659y", "_score": 1.5367417, "_routing": "0" }, { "_index": "starletwars", "_type": "_doc", "_id": "2_Vdy2IBkmPuaFRg659y", "_score": 1.5367417, "_routing": "0" }, { }, "_index": "starletwars", "_type": "_doc", "_id": "3PVdy2IBkmPuaFRg659y", "_score": 1.5367417, "_routing": "0"
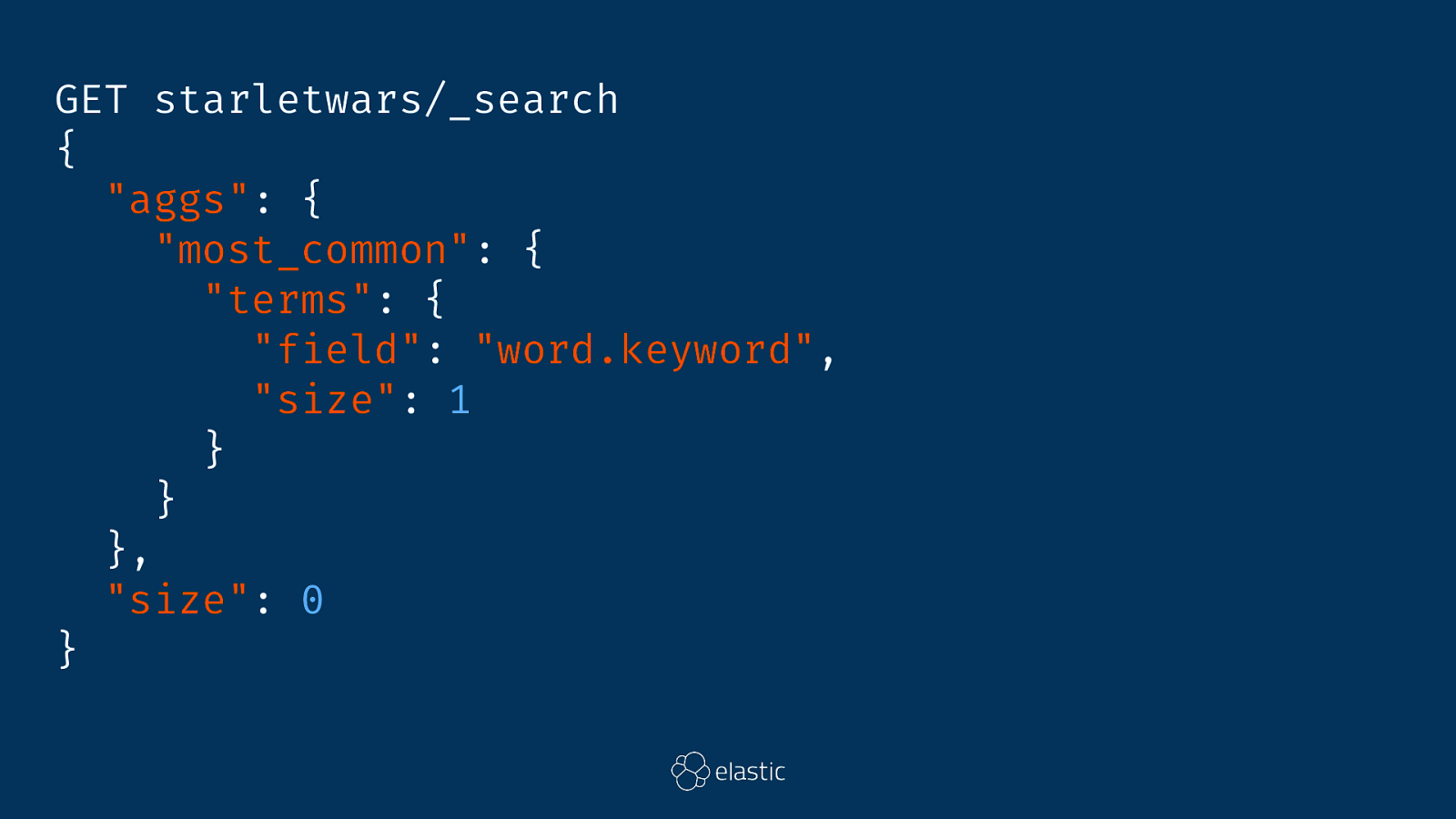
GET starletwars/_search { "aggs": { "most_common": { "terms": { "field": "word.keyword", "size": 1 } } }, "size": 0 }

{ } "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 288, "max_score": 0, "hits": [] }, "aggregations": { "most_common": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 224, "buckets": [ { "key": "Luke", "doc_count": 64 } ] } }

Change for the Cardinality Count?


Conclusion

Tradeoffs...

Consistent Available Partition Tolerant Fast Accurate Big

Questions? Philipp Krenn PS: Stickers @xeraa

The CAP theorem is widely known for distributed systems, but it's not the only tradeoff you should be aware of. For datastores there is also the FAB theory and just like with the CAP theorem you can only pick two:
- Fast: Results are real-time or near real-time instead of batch oriented.
- Accurate: Answers are exact and don't have a margin of error.
- Big: You require horizontal scaling and need to distribute your data.
While Fast and Big are relatively easy to understand, Accurate is a bit harder to picture. This talk shows some concrete examples of accuracy tradeoffs Elasticsearch can take for terms aggregations, cardinality aggregations with HyperLogLog++, and the IDF part of full-text search. Or how to trade some speed or the distribution for more accuracy.
 for free. You
can too.
for free. You
can too.
Video
Buzz and feedback
Here’s what was said about this presentation on social media.